
[▲ 문대경 아이펀팩토리 대표]
문대경 대표는 서울대 컴퓨터 공학과를 졸업하고 미국 UC Berkeley 에서 컴퓨터 공학 박사 학위를 수여하였고, 1999년 넥슨 입사 후 2005년까지 넥슨에서 출시되는 다수의 게임 개발 프로젝트에서 서버 프로그램을 책임졌습니다.
아이펀팩토리가 개발한 '아이펀 엔진'은 네트워크 처리, DB처리, 분산 처리 등 게임 서버 구현에 필요한 필수 기능을 제공하여 효율적인 게임 개발이 가능하게 하는 게임 서버엔진입니다.
열 번째 시간으로, 인터넷 세상에서의 캐싱 (caching)과 게임에서 '캐시'가 어떻게 동작하고 어떤 장단점이 있는지 좀 더 자세히 살펴보겠습니다.
* 본 내용은 본지의 편집방향과 일치하지 않을 수도 있습니다.
컴퓨터 공학에서 캐시(cache) 는 굉장히 광범위하게 사용되는 개념이다. CPU 의 사양을 기재할 때 어김없이 등장하며, 하드디스크 스펙에서도 “디스크 버퍼" 라는 이름으로 표시되고, 인터넷 뱅킹이나 관공서 웹사이트에서 뭔가 안될 때 브라우저 설정 들어가서 삭제하라고 안내 받기도 하며, 웹사이트가 잘 되더라도 민망한 기록을 지우기 위해 일부러 지우기도 하는 대상이다. (개인적으로는 이럴 때 브라우저 캐시를 지우기 보다는 in-private browsing 이나 incognito window 를 추천한다.)
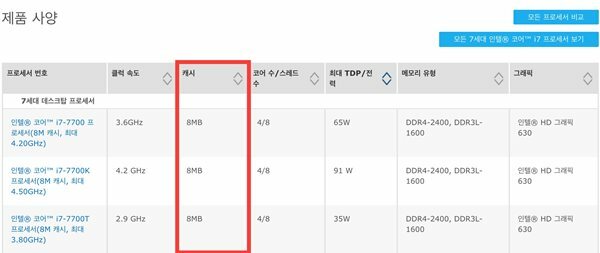

■ 캐시는 책장에 있는 책을 책상 위에 올려두는 것과 같다.
캐시(cache) 는 “은닉처" 라는 뜻의 영어 단어인데, 현금을 의미하는 cash 와 발음이 똑같아서, 컴퓨터 공학 교재에서는 캐시를 표시할 때 “$” 로 표시하기도 한다. 캐시는 매번 데이터 소스로부터 읽어 들이는 것이 상당한 시간이 걸릴 때, 처음 읽어 들인 데이터를 임시로 저장해두고 두 번째부터는 데이터 소스까지 가지 않고 데이터를 반환하기 위한 공간이다. 마치 매번 책장에서 책을 꺼내 오는 대신 자주 쓰는 책은 책상 위에 책을 놓아두는 것과 같은 이치다.
이 동작 방식을 간단히 표현하면, “캐시에 원하는 데이터가 있어? 없다고? 그럼 데이터 소스로부터 가져와야겠네.. 있어? 그럼 바로 캐시에서 읽어오고…” 가 되는 것이다.
■ 캐시의 가정과 성능을 좌우하는 변수들
여기에는 몇 가지 놓치지 말아야 될 사실들이 있는데, 먼저 처음 한 번은 어쩔 수 없이 데이터 소스로부터 읽어와야 된다는 것이고 (cache miss 라고 한다), 캐시에서 읽어 들이는 것은 (cache hit 이라고 한다) 데이터 소스로부터 데이터를 읽는 것보다 훨씬 더 빨라야 한다는 것이다. 그렇지 않으면 그냥 매번 데이터 소스에서 날로 읽어오는 것보다 못하게 된다.
지금까지의 설명대로라면 캐시는 무조건 좋은 것처럼 생각될 수도 있지만, 세상에 공짜는 없다. 위의 설명에 따르면, 캐시를 도입함에 따라 이전에는 없었던 “캐시에 원하는 데이터가 있어?” 라는 작업이 매번 발생하게 된다. 이 과정 때문에, 만일 데이터가 없을 확률이 꽤 높다면 캐시를 도입함에 따라 오히려 성능이 떨어지게 된다. 다시 말해 캐시의 도입 여부는 데이터 접근 패턴에 따라 결정해야 된다.
데이터 접근 패턴은 크게 다음 두 가지 측면에서 판단한다.
1. 같은 데이터가 근 시간 내에 반복해서 접근되는가? 이는 별로 기억하지 않아도 되는 표현으로 temporal locality 라고 하는데, 같은 데이터가 반복해서 접근된다면 캐시에 올려두는 효과가 더 커지기 때문이다. 정말 자주 쓰는 책이라면 책상 위에 항상 있는 것이 좋은 것과 마찬가지다.
2. 두 번째로는 완전히 같은 데이터일 필요는 없지만, 그 데이터 근처의 것들이 같이 접근되는가 하는 것이다. 역시 별로 기억할 필요 없는 표현으로 spatial locality 라고 한다. 이는 컴퓨터가 데이터를 읽어올 때 사람과는 다르게, 정확히 그 데이터만 읽어오는 게 아니라 편의상 뭉텅이 단위로 읽어온다는 특성에 기인한다. 예를 들어, 책을 4권 단위로 책상에 옮기게끔 되어있다고 해보자. 마음의 소리를 정주행하는 사람에게 이는 책장까지 가지 않아도 되는 개이득의 상황이지만, 1권 다음에 7권을 읽는 등 마구잡이로 읽는 사람에게는 별로 도움이 안 되는 상황이다.
위에 설명한 것들을 식으로 나열해보면 다음과 같이 생각할 수 있을 것이다.
캐시 도입에 따라 데이터를 읽는데 걸리는 시간의 기댓값
= 캐시에 데이터가 있는지 존재하는 확인 시간
+ 데이터가 캐시에 있을 확률 x 캐시로부터 읽어 들이는 시간
+ 데이터가 캐시에 없을 확률 x (원본을 읽어오는 시간 + 캐시에 이를 복사해두는 시간)
= 캐시에 데이터가 있는지 존재하는 확인 시간
+ 데이터가 캐시에 있을 확률 x 캐시로부터 읽어 들이는 시간
+ 데이터가 캐시에 없을 확률 x (원본을 읽어오는 시간 + 캐시에 이를 복사해두는 시간)
이렇게 되는 것이다. 앞서 설명한 데이터 접근 패턴은 데이터가 캐시에 있을 확률을 높이는 역할을 한다. 또한, 높은 CPU 캐시 사이즈나 브라우저 캐시 사이즈는 데이터를 캐시에 더 많이 올릴 수 있게 해주기 때문에 마찬가지로 데이터가 캐시에 있을 확률을 높여준다. 그렇지만 지나치게 큰 캐시 사이즈는 캐시에 데이터가 있는지 확인하는 시간을 길게 만들기 때문에 마냥 크게 할 수는 없다.
그리고 앞서 설명한 대로 캐시로부터 읽어 들이는 시간은 원본을 읽어오는 시간보다는 훨씬 짧아야 효과가 커진다.
■ 인터넷 세상에서 캐시의 역할
사실 캐시는 컴퓨터 구조에서 처음 도입된 개념이다. (적어도 컴퓨터 구조 관련 베스트셀러 교재를 쓰신 大家 David Patterson 교수님의 말씀에 의하면 그렇다.) 그런데 대체 왜 갑자기 이런 말을 한단 말인가? 여기는 컴퓨터 구조 수업 시간도 아닌데. 그 이유는 이 캐시라는 것이 현재 인터넷을 지탱하고 있는 기반 기술이라고 해도 과언이 아니기 때문이다.
웹 캐싱 - 브라우저 캐싱
가장 쉽게 생각할 수 있는 것이 글의 처음에서 예를 든 브라우저의 캐싱 공간이다. 이전에 열었던 페이지, 혹은 이전에 열었던 그림 등을 저장해 두었다가 다음에 같은 페이지, 그림을 서버까지 가지 않고 캐시에서 읽어 들인다. 캐시 덕분에 사용자는 웹 서핑이 빠르다고 느끼게 되고, 서버 입장에서도 불필요한 과부하를 받지 않게 된다.

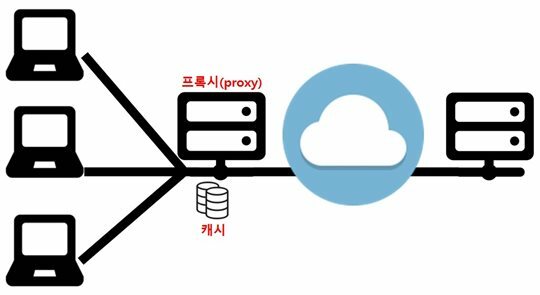
웹 캐싱 - 프록시(proxy)
웹 페이지를 캐싱하는 다른 방식으로 웹 브라우저와 서버 사이에 proxy 라는 것을 두는 방식이다. 사실 proxy는 “대리인” 이라는 뜻의 영어 단어로서, 중간에서 뭔가를 대신해주는 것을 프록시라고 한다. 중간에 있으면서 바이러스 체크나 보안 규정 위반 확인 등 해줄 수 있는 것들이 많이 있는데, 그중에서 간단한 형태로 “대신 웹 페이지를 긁어다 주는 일을 해줄 수 있다” 그리고 이 과정에서 자신이 긁어다 건네주는 페이지나 그림 등을 캐싱할 수 있다.
저 앞에서 같은 데이터가 자주 접근될 확률이 높으면 캐시 성능이 좋아진다고 했던 것이 기억나는가? 앞의 브라우저 캐싱은 각각의 컴퓨터 단위로 캐싱을 하기 때문에 이 확률이 높지 않을 수 있다. 하지만, 프록시의 경우 여러 컴퓨터로부터 요청을 받고 처리하다 보니 이 확률을 높일 수 있게 된다.
DNS 캐싱
앞에서 인터넷이 캐싱 덕분에 돌아간다고 이야기했는데, 이는 거의 DNS 를 염두에 두고 한 말이다. 우리는 www.inven.co.kr 라는 이름을 치면 IP 주소라는 것으로 변환되어 통신된다는 것은 알고 있다. 이처럼 사람이 읽을 수 있는 주소를 IP 로 바꿔주는 것을 DNS이라고 한다. 아마 다들 잘 알고 있는 단어일 것이다.
그런데 DNS 는 주소를 변환하기 위해서 맨 오른쪽부터 마침표 단위로 끊어서 그것을 관리하는 서버를 두게 된다. 그리고 그 순서대로 계속해서 담당 서버의 IP 를 물어보는 방식으로 동작한다.
예를 들면 위의 주소에서는 맨 오른쪽에 kr 이라는 것이 나오게 되는데, 이 서버는 그다음 마침표인 co.kr 이나 ac.kr 등을 담당하는 서버의 IP 주소를 기억하게 된다. 그리고 다시 co.kr 을 담당하는 서버는 inven.co.kr 이라는 이름을 관리하는 서버의 IP 주소를 기억한다. 마지막으로 inven.co.kr 을 담당하는 서버에게 물어봐서 www.inven.co.kr 의 IP 를 알아낸다.
복잡하니까 다시 정리해보면,
1. 최상위 도메인 서버로부터 kr 을 담당하는 서버의 IP 를 알아낸다. 그걸 A 라고 하자.
2. A 서버에 co.kr 을 누가 담당하는지 IP 를 물어본다. 그걸 B 라고 하자.
3. B 서버에 inven.co.kr 을 누가 담당하는지 IP 를 물어본다. 그걸 C 라고 하자.
4. C 서버에 www.inven.co.kr 의 IP 를 물어본다. 이걸 D 라고 하자.
5. 이제 브라우저는 D 라는 IP 주소로 패킷을 보낸다.
2. A 서버에 co.kr 을 누가 담당하는지 IP 를 물어본다. 그걸 B 라고 하자.
3. B 서버에 inven.co.kr 을 누가 담당하는지 IP 를 물어본다. 그걸 C 라고 하자.
4. C 서버에 www.inven.co.kr 의 IP 를 물어본다. 이걸 D 라고 하자.
5. 이제 브라우저는 D 라는 IP 주소로 패킷을 보낸다.
생각보다 상당히 많은 단계를 거친다. 그리고 모든 단계에서 캐싱이 일어난다. 예를 들어 1단계에서는 매번 kr 을 담당하는 서버의 IP 을 알아내지 않고 그걸 저장해뒀다가 다음에 활용한다. 2단계에서는 co.kr 을 담당하는 서버의 IP 를 저장해둔다.. 이런 방식으로 맨 마지막 단계인 5단계에서는 우리 컴퓨터에서도 www.inven.co.kr 의 IP 를 저장해두는 식이다.
만일 DNS 에 이런 캐싱이 없다면 어떤 일이 발생할까? IP 를 가지고 웹 페이지를 여는 사람들이 거의 없다는 가정하에 대부분 www.inven.co.kr 같은 이름을 쓸 것이다. 그러니 한국의 모든 트래픽은 1단계에서 모두 같은 서버를 찾아가게 된다. 그리고 그 서버는 부하를 감당하지 못하고 죽게 될 것이다. 실제로 2002년에 최상위 (top-level dns, TLD) DNS 서버를 DDoS 공격해서 인터넷망이 마비된 유명한 사건이 있었다.
■ 게임에서 캐시의 역할
이제 살펴본 것들을 응용해볼 시간이다. 게임에서는 어떤 것들이 캐싱이 가능할까?
가장 먼저, 브라우저 캐싱처럼 컴퓨터나 스마트폰에 리소스를 저장해두는 것을 생각해볼 수 있을 것이다. 지금 리니지 레볼루션에 접속했는데 리소스 체크를 하고 업데이트된 파일이 있다고 나오는가? 내 핸드폰에 리소스 파일을 캐싱하는 것으로 생각하면 된다.
여러분이 랭킹 페이지를 띄우고 있는가? 아마 서버는 이미 계산한 랭킹 결과를 캐시에 넣어뒀다가 그걸 여러분이나 그 시간대에 랭킹 페이지를 여는 다른 유저들에게 보여주고 있을 것이다.
실시간 게임이 아닌 캔디 크러시 사가 같은 게임을 하고 있는가? 그 게임은 리소스를 핸드폰에 캐싱하지 않는다. 대신 앞에서 설명한 프록시를 이용한 웹 캐싱을 하고 있을 것이다. 즉, 추가로 필요한 리소스를 그때그때 받아오게 되는데, 그걸 담당하는 서버가 여러 유저들을 응대하기 위해서 캐시를 쓰고 있을 것이다.
이처럼 캐시는 알게 모르게 다양하게 활용되고 있다.
■ 캐시의 문제
그렇다면 캐시의 가장 큰 문제는 뭘까?
우리가 매번 서버로부터 데이터를 받아다가 쓴다면 데이터가 업데이트된 것이 모두 자연스럽게 반영이 될 것이다. 하지만, 캐시는 매번 받아다가 쓰는 것이 아니라 어딘가 가까이에 저장해두고 그걸 쓴다고 했다. 그 덕분에 네트워크 사용량은 줄지만, 나중에 서버쪽 데이터가 업데이트 되더라도 그걸 확인할 수 있는 방법이 없게 된다. 이걸 cache staleness 라고 하는데, 용어를 기억할 필요는 없을 듯하고, 대신 1) 세상에 공짜는 없다. 2) 그 때문에 캐시는 속도를 얻었지만 최신 데이터를 체크하는 복잡성이 생겼다.라고 이해하면 좋을 듯싶다.
이런 cache staleness 는 게임에서도, DNS 를 포함한 인터넷에서도, 그리고 컴퓨터 구조에서도 (특히 CPU 를 여럿 꽂는 환경에서) 모두 복잡한 문제들을 야기한다. 게임 같은 경우는 MD5 나 SHA1 이라는 체크섬을 이용하기도 하고, DNS 같은 경우는 일정 시간이 지나면 캐시된 것을 버리게 강제하는 방법 등이 쓰인다.
이번 회에서는 컴퓨터 구조에서 착안하여 많은 곳에 응용되는 캐시에 대해서 설명하고 이것이 어떻게 게임에 활용되는지 알아봤다. 아는 분으로부터 글이 너무 길어서 그냥 뒤로 가기 눌렀다는 말을 듣고 충격을 받고 분량을 줄이려고 했으나 역시 길어진 듯하다. 부디 너무 지루하지 않았길 바란다.










