
미국의 인공지능 개발사 OpenAI가 금일(16일) 텍스트만으로 영상을 제작해 내는 text-to-video AI 모델, '소라(Sora)'를 공개했다.
OpenAI에 따르면, '소라'는 최대 1분 길이의 영상을 생성하는 것이 가능하다. 기존 text-to-video 모델들이 4초 남짓한 영상을 생성할 수 있던 것과 비교하면 확연한 차이를 갖는다. 또한, 생성된 영상의 전반적인 품질은 물론, 생성된 사물의 모습이 동일하게 유지될 수 있도록 하는 등 기술이 적용됐다.
'소라'의 AI 모델 소개 페이지는 여러 인물과 특정한 동작 유형, 피사체와 배경의 정확한 디테일을 갖춘 복잡한 장면을 생성할 수 있다고 소개하고 있다. 또, 사용자가 프롬프트를 통해 요구한 내용 뿐 아니라, 이러한 요소들이 실제 세계에 어떻게 존재하는지 이해하는 기능을 갖춰 보다 사실적인 결과물을 생성하는 것이 가능하다. 홈페이지에 공개된 위 사례 또한 텍스트 프롬프트로만 제작된 영상이다.
기술 리포트에 따르면 '소라'는 1920x1080p 와이드스크린, 수직 1080x1920 사이 모든 해상도로 샘플링할 수 있다. 이를 통해 여러 다른 디바이스에 적합한 콘텐츠를 제작 가능하다. 또한, 풀 사이즈 해상도로 생성하기 전 낮은 화질로 프로토타입할 수 있는 기능도 갖추고 있다.

OpenAI는 소라를 개발하는 데 대규모 언어 모델(LLM)에서 영감을 받았다고 밝혔다. 수많은 텍스트 토큰이 수학, 자연어, 코드 등 텍스트의 양식을 통합하는 데 사용된 것과 마찬가지로, 소라는 동영상과 이미지를 '패치'라는 데이터 단위로 표현했다. 이를 통해 데이터를 표현하는 방식을 통합, 이전보다 더욱 디퓨전 모델을 고도로 훈련시킬 수 있었다는 것이 OpenAI의 설명이다.
영상을 생성하는 것 이외에도, '소라'는 다양한 상황에서 활용이 가능해 보인다. 기술 문서에 공개된 소라의 기능을 확인해 보면, 해당 AI 모델은 기존의 정지 이미지를 동영상으로 생성할 수도 있으며, 서로 다른 두 영상을 자연스럽게 이어주는 영상 또한 생성해내는 것이 가능하다. 또한, 기존 영상의 앞, 또는 뒤를 확장하는 영상을 생성해 전체 영상의 길이를 늘릴 수도 있다.

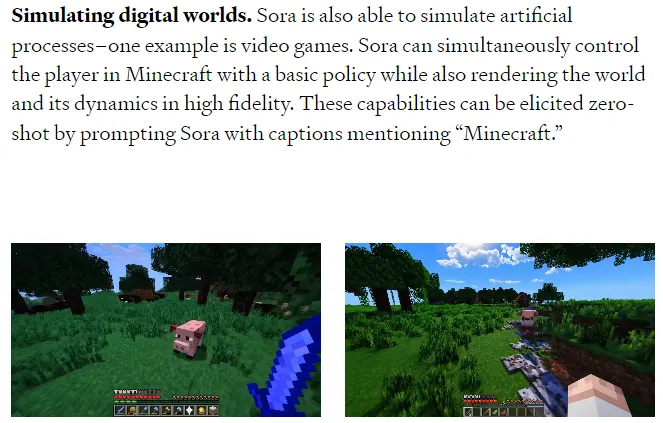
또 한 가지 놀라운 점은 현실에 존재하지 않는, 디지털 세상 또한 시뮬레이션할 수 있다는 점이다. OpenAI는 예시로 '마인크래프트'를 소개했는데, '소라'는 기본 정책에 따라 '마인크래프트'의 플레이어는 물론 그 주변 세계를 높은 충실도로 렌더링할 수 있다. "마인크래프트"라는 단어가 포함된 프롬프트만으로 실제 플레이 장면이 아닌 '마인크래프트' 영상을 생성할 수 있다는 의미다.
그러나, 아직까지 미흡한 점도 존재한다. OpenAI는 "소라가 시뮬레이터로서 수많은 한계를 보이고 있다"며, 예를 들어 유리컵이 깨질 때 파편 같은 기본적인 상호작용 수준의 물리학을 정확히 모델링하지 못한다고 전했다. 비슷하게, 음식을 먹는 것과 같은 기본적인 물리적 상호작용 등이 항상 물체 상태에 정확한 변화를 가져오는 것도 어렵다.
'소라'가 매우 사실적인 영상을 생성하는 만큼 안전 조치에 대해서도 언급했다. 현재 소라는 AI 모델의 안정성을 시험하는 '레드팀' 및 일부 비주얼 아티스트, 영화 감독 등에게 제공되었으며, 일반 사용자는 이용이 불가능하다. '레드팀'은 앞으로 오보, 혐오 콘텐츠, 성적 내용 등에 대해 해당 AI 모델을 테스트할 전망이다.
OpenAI는 소라가 영상을 생성한 시점을 알 수 있는 탐지 분류기 등 실제 영상과 오해하거나, 혼동할 수 있는 소지가 있는 경우에 도움이 되는 툴도 개발하고 있다고 전했다. 현재 DALL·E 3 등에 사용되는 안전 장치도 '소라'에게 적용이 가능해, 폭력, 성적 내용, 혐오스러운 이미지나 연예인과 유사한 이미지를 요청하는 프롬프트를 확인하고 거부한다는 것이 OpenAI의 설명이다.
아직 일반 사용자에게 배포되지 않은 만큼, Sora의 가격 정책 등 자세한 사항은 확인이 불가능하다. Sora AI 모델에 관한 보다 자세한 내용과 예시 영상은 Open AI 소개 페이지에서 살펴볼 수 있다.




















































