import numpy as np
import pandas as pd
# 시뮬레이션 설정
num_octopuses = 100000 # 문어 개수
max_attempts = 100 # 최대 강화 시도 횟수
# 강화 확률 테이블 (성공 확률, 실패 확률, 도망 확률, 보상)
upgrade_data = {
1: (1.00, 0.00, 0.00, 0),
2: (0.60, 0.40, 0.00, 1),
3: (0.50, 0.50, 0.00, 3),
4: (0.40, 0.60, 0.00, 6),
5: (0.307, 0.693, 0.00, 10),
6: (0.205, 0.765, 0.03, 15),
7: (0.103, 0.857, 0.04, 50),
8: (0.05, 0.90, 0.05, 150),
9: (0.00, 0.00, 0.00, 300), # 목표 레벨 도달 시 강화 종료
}
# 목표 레벨별 통계 저장
results = []
for target_level in range(2, 10):
total_rewards = 0
total_attempts = 0
reached_target = 0
failed_to_reach = 0
total_escapes = 0
for _ in range(num_octopuses):
level = 1
attempts = 0
escaped = False
while level < target_level and attempts < max_attempts:
success_rate, fail_rate, escape_rate, _ = upgrade_data[level]
rand_val = np.random.rand()
if rand_val < success_rate:
level += 1
elif rand_val < success_rate + fail_rate:
if level >= 3:
level -= 1
else:
total_escapes += 1
escaped = True
break
attempts += 1
total_attempts += attempts
if not escaped:
total_rewards += upgrade_data[level][3]
if level >= target_level:
reached_target += 1
elif not escaped:
failed_to_reach += 1
avg_reward = total_rewards / num_octopuses
avg_attempts = total_attempts / num_octopuses
results.append([
target_level, avg_reward, avg_attempts,
reached_target, failed_to_reach, total_escapes
])
# 결과 테이블 생성 및 출력
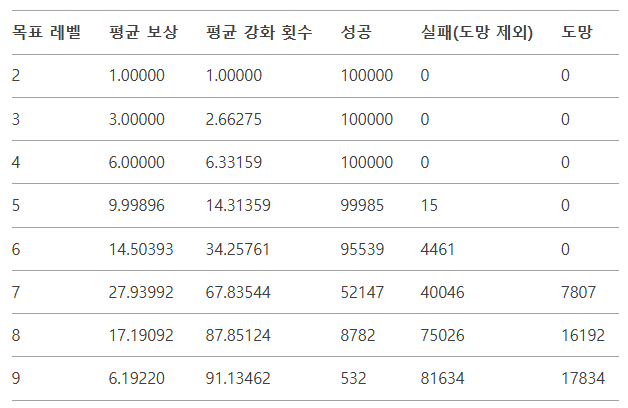
df_results = pd.DataFrame(results, columns=["목표 레벨", "평균 보상", "평균 강화 횟수", "성공", "실패(도망제외)", "도망"])
print(df_results)
 Onenap
Onenap
