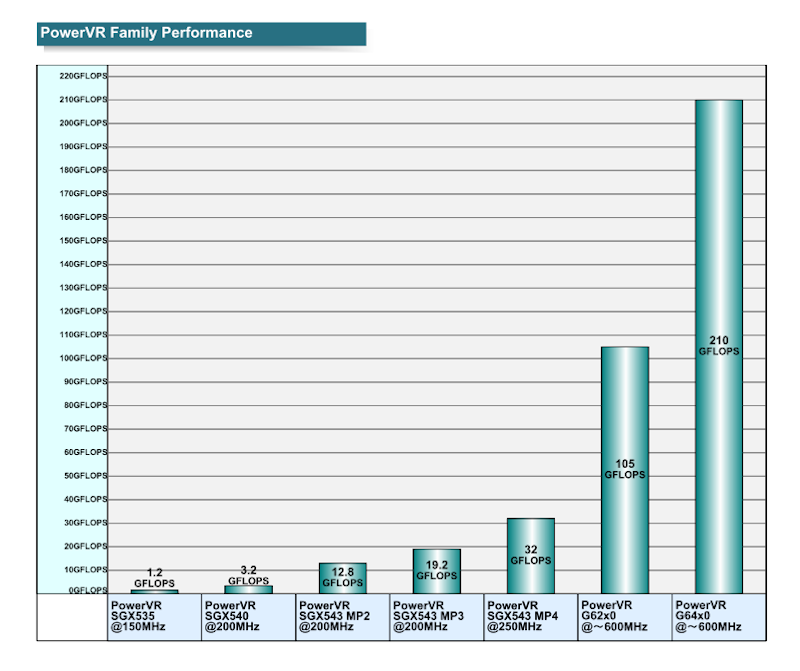
лӘЁл°”мқј GPUмқҳ м„ұлҠҘмқ„ 100GFLOPS лҢҖ
2 л…„ л°ҳ л§Ңм—җ 38 л°°мқҳ м„ұлҠҘ н–ҘмғҒ.
мқҙкІғмқҙ нғңлё”лҰҝм—җм„ң к·ёлһҳн”Ҫ м„ұлҠҘ н–ҘмғҒ мҶҚлҸ„мқҙлӢӨ.
мҙҲкё° iPadм—җм„ңлҠ” 2GFLOPSмқҙм—ҲлӢӨ
GPUмқҳ мғқ м—°мӮ° м„ұлҠҘмқҖ мөңмӢ iPad (4)м—җм„ңлҠ” 76.8GFLOPSлЎң м№ҳмҶҹм•ҳлӢӨ.
PCмқҳ м„ёкі„м—җм„ңмқҳ мҷ„л§Ңн•ң м„ұлҠҘ н–ҘмғҒкіјлҠ” м „нҳҖ лі„к°ңмқҳ м„ұлҠҘ кіЎм„ мқҙ
лӘЁл°”мқј мһҘм№ҳмқҳ м„ёкі„м—җм„ң мқјм–ҙлӮҳкі мһҲлӢӨ.
лӘЁл°”мқј мһҘм№ҳлҠ” ARM CPU мҪ”м–ҙ м„ұлҠҘмқ„ м җм җ н–ҘмғҒмӢңнӮӨкі мһҲлӢӨ.
к·ёлҹ¬лӮҳ, GPU мҪ”м–ҙмқҳ м„ұлҠҘ мғҒмҠ№мқҖ CPU мҪ”м–ҙмқҳ к·ёкІғмқ„ нӣЁм”¬ лҠҘк°Җ.
к·ё л°°кІҪм—җлҠ” нғңлё”лҰҝ / мҠӨл§ҲнҠё нҸ°мқҳ кёүкІ©н•ң нҷ”л©ҙ н•ҙмғҒлҸ„ н–ҘмғҒкіј
3D кІҢмһ„мқҳ м№ЁнҲ¬,
к·ёлҰ¬кі к·ёлһҳн”Ҫ м„ұлҠҘмқ„ м§Җмӣҗ лӘЁл°”мқј л©”лӘЁлҰ¬ кё°мҲ мқҳ л°ңм „мқҙмһҲлӢӨ.
к·ё кІ°кіј, нҳ„мһ¬мқҳ лӘЁл°”мқј SoC (System on a Chip)мқҳ лӢӨмқҙлҠ”
GPU мҪ”м–ҙк°Җ лҢҖл¶Җ분мқ„ м°Ём§Җн•ҳкІҢлҗҳм—ҲлӢӨ.
нҠ№нһҲ мЈјлӘ©н• л§Ңн•ң кІғмқҖ Appleмқҳ SoC
н•ҳм§Җл§Ң нғҖмӮ¬лҸ„ Appleм—җ лҢҖн•ӯн•ҳкё° мң„н•ҙ SoC мҶҚмқҳ GPU мҪ”м–ҙлҘј к°•нҷ”н•ҳкі мһҲлӢӨ.
м Ғм–ҙлҸ„ нғңлё”лҰҝмқҖ нҳ„мһ¬мқҳ мЈјм—ӯмқҖ GPU мҪ”м–ҙлЎң CPU мҪ”м–ҙлҠ” мЎ°м—°мқҙлӢӨ.
Appleмқҙ мһҗмӮ¬мқҳ лӘЁл°”мқј SoC "Apple Ax"мӢңлҰ¬мҰҲ GPU мҪ”м–ҙм—җ мұ„мҡ©н•ҳкі мһҲлҠ” кІғмқҖ
Imagination Technologiesмқҳ PowerVR SGX кі„ н•өмӢ¬мқҙлӢӨ.
AppleмқҖ мһҗмӮ¬м—җм„ң GPU мҪ”м–ҙмқҳ к°ңл°ңмқ„ мӢңмһ‘н•ҳкі мһҲм§Җл§Ң,
мһҗмӮ¬ мҪ”м–ҙлЎң лҢҖмІҙ лҗ л•Ңк№Ңм§Җ PowerVRлҘј кі„мҶҚ м„ ліҙмқёлӢӨ.
Imagination TechnologiesлҸ„ Apple к°•н•ң к·ёлһҳн”Ҫ м„ұлҠҘ мҡ”кө¬м—җ л¶Җмқ‘н•ҳкё° мң„н•ҙ,
GPU мҪ”м–ҙлҘј кі„мҶҚ мҰқк°Җн•ҳкі мһҲлӢӨ.
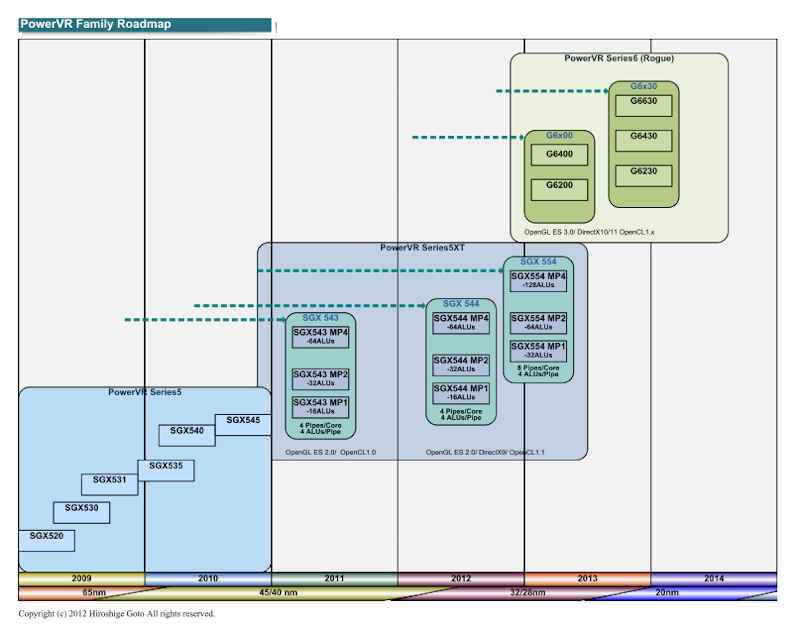
к·ёлҰ¬кі м§ҖкёҲмқҖ м°Ём„ёлҢҖ PowerVR Series6 (Rogue)лЎң ліҖнҷ”к°Җ мӢңмһ‘лҗҳкі мһҲлӢӨ.
PowerVR лЎңл“ңл§ө
м•„лһҳмқҳ м°ЁнҠёлҠ” Imagination Technologiesмқҳ Web мӮ¬мқҙнҠём—җмһҲлҠ”
The rise of GPU compute "лқјлҠ” лё”лЎңк·ё кё°мӮ¬м—җ мһҲлҚҳ м°ЁнҠёлҘј л°”нғ•мқҳ кІғмқҙлӢӨ.
мӣҗлһҳ м°ЁнҠём—җлҠ” GFLOPSмқҳ мҲ«мһҗлҠ” л“Өм–ҙ мһҲм§Җ м•Ҡм•ҳкё° л•Ңл¬ём—җ, кі„мӮ°н•ҳкі ліҙмҷ„н–ҲлӢӨ.
PowerVR Series6мқҳ GFLOPS к°’мқҖ мҳ¬н•ҙ (2012 л…„) 1 мӣ”м—җ
Rogue м•„нӮӨн…ҚмІҳ мҪ”м–ҙлҘј л°ңн‘ңн–Ҳмқ„ л•Ңмқҳ мҲ«мһҗлҘј л„Јкі мһҲлӢӨ.
мӣҗлһҳ к·ёлҰјмқҳ м°ЁнҠё 비мңЁмқҖ м•„лһҳмқҳ к·ёлҰјм—җ м“ҙ GFLOPS к°’кіј мқјм№ҳн•ҳкі мһҲлӢӨ.
PowerVR Series5 / 6 GPU м„ұлҠҘ
мң„ м°ЁнҠёлҘј ліҙл©ҙ,
Imagination Technologiesк°Җ GPU м„ұлҠҘмқ„ кёүмҰқмӢңнӮӨкі мһҲлҠ” кІғмқҙліҙмқёлӢӨ.
к·ёлҰјм—җм„ңлҠ” мҳӨлҘёмӘҪмқҳ л‘җ кё°л‘Ҙмқҙ PowerVR Series6 мӢңлҰ¬мҰҲ
G64x0н•ҳл©ҙ 62x0мқҳ м„ұлҠҘмқҙлӢӨ.
лӮҙл…„ (2013 л…„)м—җм„ң мӢңмһҘм—җ л“ұмһҘн•ҳлҠ” Rogue м•„нӮӨн…ҚмІҳм—җм„ң
100GFLOPSмқҳ м„ұлҠҘ лІ”мң„м—җ л“Өм–ҙк°Җ л“ңл””м–ҙ PC к·ёлһҳн”Ҫмқҳ м„ёкі„м—җ м ‘к·јн•ңлӢӨ.
лҸҷмһ‘ мЈјнҢҢмҲҳлҘј л‘җ л°°лЎң мқёмғҒ Rogue м•„нӮӨн…ҚмІҳ
PowerVR Series6мқҳ м„ұлҠҘмқҙ
кё°мЎҙмқҳ Apple м ңн’Ҳм—җ 비н•ҙ м–ҙл–»кІҢлҗҳлҠ”м§Җ 비көҗн•ҳл©ҙ м•„лһҳ к·ёлҰјкіј к°ҷлӢӨ.
мҙҲкё° iPadм—җм„ң iPad (4)к№Ңм§Җмқҳ мЈјмҡ” м ңн’Ҳмқҳ м„ұлҠҘ л°Ҹ ALU
(Arithmetic Logic Unit, м—°мӮ° мң лӢӣ) мҲҳлҘј PowerVR Series6мқҳ 1 м„ёлҢҖмҷҖ 비көҗн•ҳкі мһҲлӢӨ.
AppleмқҖ л§№л ¬н•ң кё°м„ёлЎң ALUлҘј лҠҳлҰ¬кі к·ё кІ°кіј м„ұлҠҘмқҙ кёүмҰқн•ң кІғмқ„ мһҳ м•ҲлӢӨ.
Apple м ңн’Ҳмқҳ н”„лЎңм„ём„ң м„ұлҠҘ
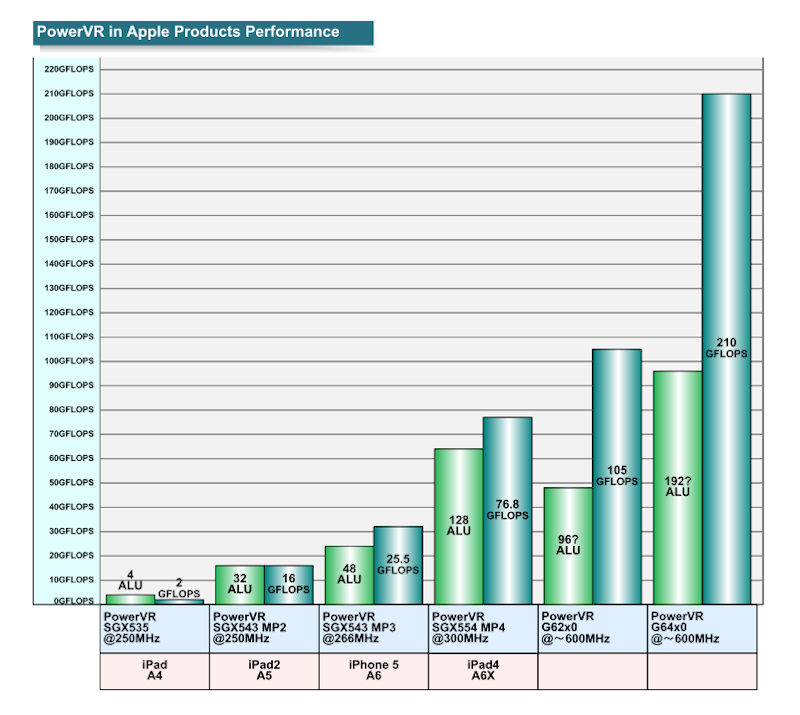
к·ёлҰ¬кі PowerVR Series6 м„ёлҢҖлҠ” нҳ„мһ¬
нғңлё”лҰҝ мөңкі м„ұлҠҘмқҳ iPad (4)лҘј мӣҗмӢң м„ұлҠҘ лҠҘк°Җн•ҳлҠ” кІғмқ„ м•ҢмҲҳмһҲлӢӨ.
PowerVR Series6мқҳ м ң 1 м„ёлҢҖлҠ” 28nm н”„лЎңм„ёмҠӨк°Җ нғҖкІҹ кІғмңјлЎң ліҙмқҙкё° л•Ңл¬ём—җ,
Appleмқҙ лӮҙл…„ (2013 л…„)м—җ 32nm (A6/A6X)м—җм„ң 28nmлЎң мқҙн–үн•ҳл©ҙ
PowerVR Series6мқ„ мӮ¬мҡ©н• мҲҳлҸ„мһҲлӢӨ.
AppleмқҖ PowerVR Series6лҘј мӮ¬мҡ©н•ҳлҠ” кІғмңјлЎң, нҳ„мһ¬мқҳ м„ұлҠҘ кіЎм„ мқ„ мң м§Җн• мҲҳмһҲмқ„ кІғ к°ҷлӢӨ.
PowerVR Series6мқҳ м—°мӮ° м„ұлҠҘмқҙ лҶ’мқҖ кІғмқҖ
Imagination Technologiesк°Җмқҙ м„ёлҢҖм—җ м•„нӮӨн…ҚмІҳлҘј мқјмӢ н•ң л•Ңл¬ёмқҙлӢӨ.
PowerVR Series6лҠ” GPU мҪ”м–ҙмқҳ кө¬м„ұмқ„ л°”кҫёкі ,
лҢҖк·ңлӘЁ н”„лЎңм„ём„ң кө¬м„ұмқ„ мүҪкІҢ лҪ‘мқ„ мҲҳ мһҲлҸ„лЎқн–ҲлӢӨ.
GPU мҪ”м–ҙ лӮҙл¶Җмқҳ лӘ…л № м ңм–ҙлҘј нҒ¬кІҢ ліҖкІҪн•ҳм—¬
лӢӨмқҙ л©ҙм Ғ л°Ҹ м „л Ҙ лӢ№ м„ұлҠҘмқ„ лҒҢм–ҙ мҳ¬лҰ¬л Өн•ҳкі мһҲлӢӨ.
лҳҗн•ң, лҸҷмһ‘ мЈјнҢҢмҲҳлҠ” кё°мЎҙмқҳ 200 ~ 300MHz лҢҖм—җм„ң мөңкі 600MHzлЎң л°°м—җ мҳ¬л ёлӢӨ.
лҢҖмғҒ лҸҷмһ‘ мЈјнҢҢмҲҳлҘј мҳ¬лҰ° кІғмқҖ,
GPU мҪ”м–ҙмқҳ м—°мӮ° мң лӢӣмқҳ нҢҢмқҙн”„ лқјмқё кө¬мЎ°лҘј л°”кҫј кІғмқ„ мқҳлҜён•ҳкі мһҲмқ„ к°ҖлҠҘм„ұмқҙ лҶ’лӢӨ.
н”„лЎңм„ёмҠӨ кё°мҲ мқҳ 진нҷ” 분 л§Ң м—¬кё°к№Ңм§Җ мЈјнҢҢмҲҳлҘј мҳ¬лҰ¬лҠ” кІғмқҖ м–ҙл ө кё° л•Ңл¬ёмқҙлӢӨ.
н”„лЎңм„ём„ңмқҳ нҢҢмқҙн”„ лқјмқёмқ„ к№ҠкІҢн•ҳл©ҙ лҚ” лҶ’мқҖ мЈјнҢҢмҲҳм—җм„ң лҸҷмһ‘ к°ҖлҠҘн•ҳкІҢлҗңлӢӨ.
кё°мЎҙмқҳ PowerVRлҠ” л¶ҖлҸҷ мҶҢмҲҳм җ м—°мӮ° мң лӢӣмқ„ 4 мӮ¬мқҙнҒҙмқҳ мӢӨн–ү м§Җм—°мңјлЎң лҸҢлҰ¬лҠ”
нҢҢмқҙн”„ лқјмқё кө¬мЎ°лҘј мұ„нғқн•ҳкі мһҲм—ҲлӢӨ.
мҰү, м—°мӮ° мң лӢӣмқҖ 4 лӢЁкі„мқҳ нҢҢмқҙн”„ лқјмқё кө¬мЎ°лЎңлҗҳм–ҙ мһҲм—ҲлӢӨ.
кё°мЎҙмқҳ PowerVRмқҳ мҠӨл Ҳл“ң мҠӨмјҖмӨ„лҹ¬

1 м—°мӮ° мң лӢӣмқҙ 1 лӘ…л №мқ„ мӢӨн–үн•ҳлҠ” лҚ° 4 мӮ¬мқҙнҒҙ кұёлҰ°лӢӨ.
к·ёлҹ¬лӮҳ нҢҢмқҙн”„ лқјмқё нҷ”лҗҳм–ҙ мһҲкё° л•Ңл¬ём—җ
мғҲлЎңмҡҙ лӘ…л №мқҳ мӢӨн–үмқ„ 1 мӮ¬мқҙнҒҙл§ҲлӢӨ мӢңмһ‘мӢңнӮ¬ мҲҳмһҲлӢӨ.
PowerVR м•„нӮӨн…ҚмІҳмқҳ кІҪмҡ°лҠ”мЈјкё°л§ҲлӢӨ лӢӨлҘё мҠӨл Ҳл“ңмқҳ лӘ…л №мқ„ мӢӨн–үн•ңлӢӨ.
л”°лқјм„ң 4 мӮ¬мқҙнҒҙмқҳ м§Җм—° мӢңк°„мқ„ мқҖнҸҗн•ҳкё° мң„н•ҙ 4 мҠӨл Ҳл“ңлҘј лі‘л ¬лЎң мӢӨн–үн•ҳкІҢлҗңлӢӨ.
мқҙлІҲ Imagination Technologiesк°Җ PowerVR Series6мқҳ лҸҷмһ‘ мЈјнҢҢмҲҳлҘј
2 л°°лЎң лҒҢм–ҙ мҳ¬лҰҙ мҲҳлҠ” 4 лӢЁкі„мқҳ нҢҢмқҙн”„ лқјмқёмқ„ 8 лӢЁкі„лЎң лҶ’мқҙлҠ” кІғмқ„ мқҳлҜён•ҳлҠ” кІғмңјлЎң
추측лҗңлӢӨ.
к·ё кІҪмҡ°, лӘ…л №мқҳ мӢӨн–ү м§Җм—° мӢңк°„мқҖ 4 мӮ¬мқҙнҒҙм—җм„ң 8мЈјкё° лҠҳм–ҙлӮңлӢӨ.
л”°лқјм„ң мӢӨн–ү м§Җм—° мӢңк°„мқ„ мқҖнҸҗн•ҳкё° мң„н•ҙ 2 л°°мқҳ 8 мҠӨл Ҳл“ңк°Җ н•„мҡ”н•ҳлӢӨ.
мҰү, PowerVR Series6м—җм„ңлҠ” кі мЈјнҢҢ нҷ”лҘј мң„н•ҙ мҰүмӢң мӢӨн–үн• мҲҳмһҲлҠ” мҠӨл Ҳл“ң мҲҳлҘј лҠҳл Өм•јн•ңлӢӨ.
к·ёлҰ¬кі мқҙлҘј мң„н•ҙ нҳ„мһ¬ 16 н•ӯлӘ© мҠӨл Ҳл“ң н’ҖлҸ„ нҷ•мһҘ н• н•„мҡ”к°ҖмһҲлӢӨ.
л©”лӘЁлҰ¬ м•Ўм„ёмҠӨ м§Җм—° мӮ¬мқҙнҒҙ мҲҳк°Җ мҰқк°Җ л•Ңл¬ёмқҙлӢӨ.
PowerVRмқҳ мҠӨл Ҳл“ң мҠӨмјҖмӨ„л§Ғ
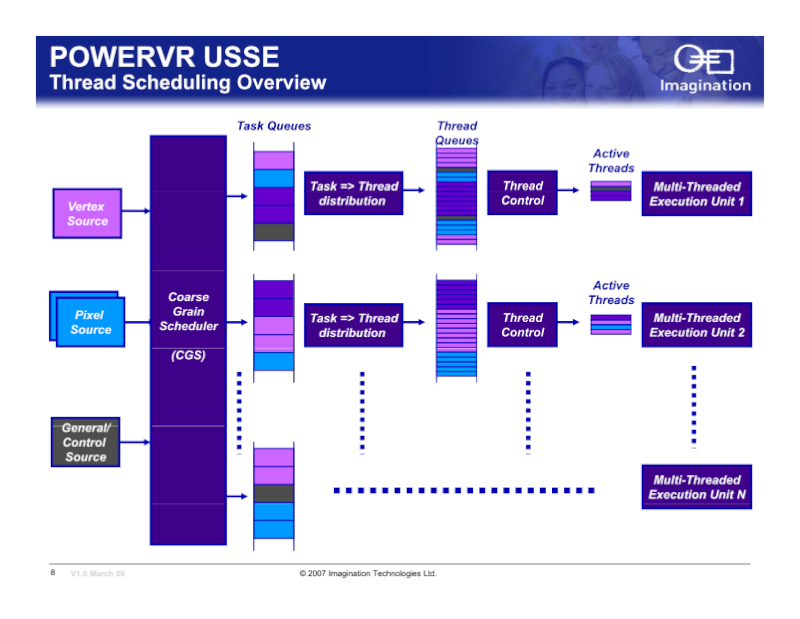
Imagination Technologiesк°Җ нҢҢмқҙн”„ лқјмқёмқ„ к№ҠкІҢн–ҲлӢӨн•ҳл©ҙ мқҙл ҮкІҢ м ңм–ҙн•ҙм•јн•ңлӢӨ
мҠӨл Ҳл“ң мҲҳк°Җ мҰқк°Җн•ҳкё° мң„н•ҙ мҠӨл Ҳл“ң м ңм–ҙ л¶Җ분мқҳ мҳӨлІ„ н—Өл“ңк°Җ лҠҳм–ҙлӮңлӢӨ.
лҳҗн•ң нҢҢмқҙн”„ лқјмқёмқ„ к№ҠкІҢн•ҳл©ҙ latch нҡҢлЎңк°Җ мҰқк°Җ нҒҙлҹӯ л°°нҸ¬нҢҗлҸ„ ліөмһЎн•ҳкё° л•Ңл¬ём—җ
м „л Ҙ мҶҢ비к°Җ лҠҳм–ҙлӮңлӢӨ.
к·ёлҹ¬лӮҳ к·ёл§ҢнҒјмқҳ мһҘлӢЁм җмқ„ м§Җл¶Ҳн•ҙлҸ„, кұё л§һлҠ” м„ұлҠҘ н–ҘмғҒмқ„ м–»мқ„ мҲҳ мһҲлӢӨкі нҢҗлӢЁн•ң кІғмқҙлӢӨ.
лҚ§л¶ҷм—¬м„ң,
AMDлҸ„ кіјкұ° ATI Technologies мӢңлҢҖм—җ 비мҠ·н•ң нҢҢмқҙн”„ лқјмқёмқҳ мӢ¬нҷ”лҘј н–үн•ҳкі мһҲлӢӨ.
Radeon HD 2900 (R600)мӢң лӘ…л № мӢңнҖҖм„ңлҘј мқҙмӨ‘мңјлЎңн•ҳм—¬
кё°мЎҙмқҳ 4 мӮ¬мқҙнҒҙм—җм„ң 8 мӮ¬мқҙнҒҙлЎң мӢӨн–ү м§Җм—° мӢңк°„ мқҖнҸҗмқҳ мӮ¬мқҙнҒҙ мҲҳлҘј лҠҳл ёлӢӨ.
SIMD нҸӯмқҙ PowerVR Series5м—җм„ң Rogueм—җм„ң нҒ¬кІҢ ліҖнҷ”?
гҖҖ
лҸҷмһ‘ мЈјнҢҢмҲҳлҘј лҶ’мқҙлҠ” н•ңнҺё,
PowerVR Series6м—җм„ң м»ЁнҠёлЎӨ мҳӨлІ„ н—Өл“ңлҘј мӨ„мқј к°ңлҹүлҸ„ 진н–үлҗңлӢӨкі ліҙ여진лӢӨ.
Imagination Technologiesк°Җ мҳ¬н•ҙ (2012 л…„) 8 мӣ”м—җ м—…лҚ°мқҙнҠё лҗң
"PowerVR Performance Recommendations"лқјлҠ” л¬ём„ңм—җ
кё°мЎҙмқҳ PowerVR Series5мҷҖ PowerVR Series6 н”„лЎңк·ёлһҳл°Қмқҳ м°Ёмқҙм—җ лҢҖн•ҙ лӢӨлЈ°мҲҳмһҲлӢӨ.
к·ёмӨ‘ 분기 мһ…лҸ„мқҳ ліҖнҷ”м—җ лҢҖн•ҙ м ҒнҳҖмһҲлӢӨ.
мқјл°ҳм ҒмңјлЎң GPUлҠ” SIMD нҳ•мқҳ мӢӨн–ү мң лӢӣмқ„ лҢҖ비н•ҳм—¬
м—¬лҹ¬ лҚ°мқҙн„°м—җ лҢҖн•ҙм„ң к°ҷмқҖ лӘ…л №мқ„ мӢӨн–үн•ңлӢӨ.
л”°лқјм„ң лӢӨмӨ‘ мҠӨл Ҳл“ңлҘј лІЎн„°лЎң мІҳлҰ¬н•ҳлҠ” кІҪмҡ°,
к°Ғ мҠӨл Ҳл“ңлҘј к°ңлі„м ҒмңјлЎң мЎ°кұҙ 분기н•ҳлҠ” кІҪмҡ°м—җ л¬ём ңк°Җ мғқкёҙлӢӨ.
GPUм—җм„ңлҠ” нҠ№м • 분기 мһ…лҸ„к°Җ к·ё мһ…лҸ„ мӨ‘ мЎ°кұҙ 분기лҠ”
мҷёкҙҖмғҒмқҳ 분기лҘјмӢңнӮӨлҠ” л“ұмқҳ л°©лІ•мқ„ м·Ён•ңлӢӨ.
кө¬мІҙм ҒмңјлЎңлҠ”,
н”„л Ҳл”” мјҖмқҙм…ҳмқ„ мӢӨн–үн•ҙ,
SIMDмқҳ к°Ғ л Ҳмқёмқҳ мҠӨл Ҳл“ңл§ҲлӢӨ лӘ…л №мқ„ мӢӨн–үн• м§Җ м—¬л¶Җ
(лҳҗлҠ” м—°мӮ° кІ°кіјлҘј л Ҳм§ҖмҠӨн„°м—җ кё°лЎқн•ҳкұ°лӮҳ кё°лЎқн•ҳм§Җ м•ҠлҠ”к°Җ)лҘј
л§ҲмҠӨнҒ¬ л Ҳм§ҖмҠӨн„°м—җ мқҳн•ҙ м„ нғқн•ңлӢӨ.
н”„л Ҳл”” мјҖмқҙм…ҳм—җ мқҳн•ҙ мҷёкҙҖмғҒ л ҲмқёмқҖ мҠӨм№јлқј н”„лЎңм„ём„ңлЎң лҸҷмһ‘н•ңлӢӨ.
к·ёлҹ¬лӮҳ мӢӨм ңлЎңлҠ” н•ҳл“ңмӣЁм–ҙ м ҒмңјлЎңлҠ” SIMDмқҙл©°,
н”„лЎңк·ёлһЁмқҳ мӢӨн–ү кІҪлЎңлҠ” SIMD м „мІҙм—җм„ң мқјкҙҖлҗңн•ҳкі (л¬ҙкІ°м„ұмқ„ м·Ён•ҳкі ) мӢӨн–үлҗңлӢӨ.
н”„л Ҳл”” мјҖмқҙм…ҳм—җ к·ё кІ°кіјк°Җ л°ҳмҳҒлҗҳм§Җ м•Ҡмқ„ лҝҗмқҙлӢӨ.
лҚ§л¶ҷм—¬м„ң SIMD мӢӨн–ү лӢЁмң„лҠ” NVIDIA м•„нӮӨн…ҚмІҳм—җм„ңлҠ”
32 мҠӨл Ҳл“ң,
AMD м•„нӮӨн…ҚмІҳм—җм„ңлҠ” 64 мҠӨл Ҳл“ңмқҙлӢӨ.
лІЎн„° мЎ°кұҙ 분기 м ңм–ҙ
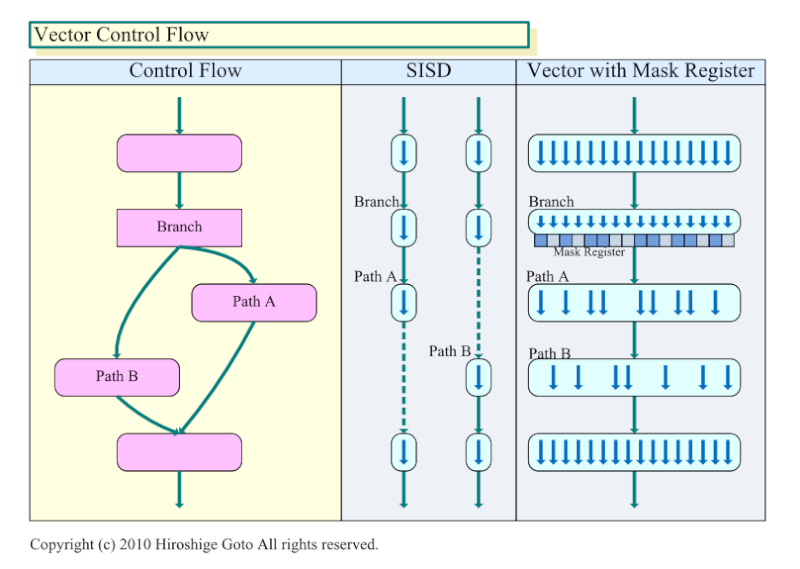
к·ёлҹ¬лӮҳ кё°мЎҙмқҳ PowerVR Series5лҠ”
к·ёлҹ¬н•ң PC мҡ© GPUмҷҖ к°ҷмқҖ нҒ° 분기 мһ…лҸ„к°Җ м—Ҷм—ҲлӢӨ.
PowerVR Series5лҠ” 1 к°ңмқҳ м •м җ лҳҗлҠ” 1 к°ңмқҳ н”Ҫм…Җ лӢЁмң„лЎң мЎ°кұҙ 분기к°Җ к°ҖлҠҘн•ҳлӢӨ.
мқҙм—җ лҢҖн•ҙм„ңлҠ” "POWERVR SGX OpenGL ES 2.0 Application Development Recommendations"лқјлҠ” Imagination Technologiesмқҳ л¬ём„ңм—җ лӘ…кё°лҗҳм–ҙмһҲлӢӨ.
PowerVR Series5м—җм„ңлҠ” мӣҗлҰ¬ м ҒмңјлЎң н”„лЎңк·ёлһЁ мӨ‘м—җ мЎ°кұҙ 분기к°ҖмһҲмқ„ кІҪмҡ°,
лІ„н…ҚмҠӨ / н”Ҫм…Җл§ҲлӢӨ лӢӨлҘё лӘ…л № мӢӨн–ү кІҪлЎңлҘј мӢӨн–үн• мҲҳмһҲлӢӨ.
к·ёлҹ¬лӮҳ мӢӨм ңлЎңлҠ” м •м җкіј н”Ҫм…Җ лӘЁл‘җ лӢӨмӨ‘ мҠӨл Ҳл“ңлЎң 분н•ҙн•ҙ лІ„лҰ¬кё° л•Ңл¬ём—җ
м—¬лҹ¬ мҠӨл Ҳл“ң лӢЁмң„лҘј к°Җм§Җкі мһҲлӢӨ.
мҳҲлҘј л“Өм–ҙ,
RGBA н”Ҫм…Җмқҙлқјл©ҙ 4 мҠӨл Ҳл“ңн•ҳлҜҖлЎң н•ҳл“ңмӣЁм–ҙ м ҒмңјлЎң
분기 мһ…лҸ„лҠ” 4 мҠӨл Ҳл“ң мқё кІғмңјлЎң ліҙмқёлӢӨ.
л°ҳл©ҙ PowerVR Series6м—җм„ңлҠ” 분기 мһ…лҸ„к°Җ лҚ” м»Ө진лӢӨкі н•ңлӢӨ.
Imagination Technologiesмқҳ л¬ём„ңм—җ л”°лҘҙл©ҙ,
н”Ҫм…Җ мүҗмқҙлҚ” н”„лЎңк·ёлһЁмқҳ 분기лҠ” н”Ҫм…Җ лӢЁмң„м—җм„ң н–үн•ҙм§ҖлҠ” кІғмқҙ м•„лӢҲлқј,
мқјкҙҖлҗҳкІҢ л°ңмғқн•ңлӢӨкі н•ңлӢӨ.
мҰү, PowerVR Series6м—җм„ңлҠ” нҒ° 분기 мһ…лҸ„лҘј к°Җ진 кІғмңјлЎң 추측лҗңлӢӨ.
PC мҡ© GPUлҠ” лӘЁл‘җ PowerVR Series5ліҙлӢӨ нӣЁм”¬ нҒ° 분기 мһ…лҸ„лҘј мұ„нғқн•ҳкі мһҲлӢӨ.
мқҙкІғмқҖ 분기 мһ…лҸ„лҘј мҳ¬л ём„ң лӘ…л № м ңм–ҙ мһҘм№ҳлҘј лӢЁмҲңнҷ”н•ҳм—¬
칩мқҳ м—°мӮ° мң лӢӣмқҳ 비мңЁмқ„ лҶ’мқј мҲҳ мһҲкё° л•Ңл¬ёмқҙлӢӨ.
мҰү, GPU мҪ”м–ҙмқҳ мқјм •н•ң лӢӨмқҙ л©ҙм ҒлӢ№ м—°мӮ° мң лӢӣмқҳ мҲҳлҘј лҠҳлҰ¬лҠ” кІғмқҙ мҡ©мқҙн•ҳкІҢлҗңлӢӨ.
PowerVR Series6к°Җ 분기 мһ…лҸ„ (= л…јлҰ¬ лІЎн„° кёёмқҙ)лҘј лҠҳл ёлӢӨн•ҳл©ҙ,
м–ҙлҠҗ м •лҸ„ нҷ•мһҘн–ҲлҠ”м§Җк°Җ нҸ¬мқёнҠёк°ҖлҗңлӢӨ.
м „м ңмқҳ "The rise of GPU compute"лқјлҠ” лё”лЎңк·ё кё°мӮ¬лҠ”
PowerVR Series6мқҳ мӢӨн–ү лӘЁлҚёмқ„ "scalar / wide SIMD execution model"лқјкі л¶ҖлҘҙкі ,
NVIDIA л°Ҹ AMDмҷҖ мң мӮ¬н•ң л°©мӢқмһ„мқ„ мӢңмӮ¬н•ҳкі мһҲлӢӨ .
мҰү, 비көҗм Ғ л„“мқҖ SIMD мң лӢӣмңјлЎң,
н”„л Ҳл”” мјҖмқҙм…ҳм—җ мқҳн•ҙ 분기лҘј м ңм–ҙн•ҳм—¬
мҠӨм№јлқј н”„лЎңм„ём„ңлЎң мһ‘лҸҷмӢңнӮӨлҠ” л°©лІ•мқ„ мұ„нғқ ліҙмқёлӢӨ.
к·ёлҹ¬лӮҳ, PowerVR Series6мқҳ SIMDмқҳ мһ…лҸ„лҠ” м•„м§Ғ нҳ„ лӢЁкі„м—җм„ңлҠ” 분лӘ…н•ҳм§Җ м•ҠлӢӨ.
PowerVRмқҳ к°ңл°ңмһҗ нҸ¬лҹјм—җм„ңлҸ„ мқҙм җм—җ лҢҖн•ҙ м§Ҳл¬ёмқҙлҗҳм–ҙ мһҲм§Җл§Ң,
Imagination Technologies мёЎмқҳ мқ‘лӢөмқҖ "м•„м§Ғ л°қнһҗмҲҳ м—ҶлӢӨ"лҠ” кІғмқҙм—ҲлӢӨ.
PowerVR Series6мқҳ мӢӨн–ү мң лӢӣмқҖ 16 ALU м”© лІҲл“Өлҗҳм–ҙ мһҲлӢӨлҠ” м •ліҙк°Җ мһҲмңјлҜҖлЎң
16-wayмқҳ SIMDк°Җ мҳҲмғҒлҗҳм§Җл§Ң,
NVIDIA л°Ҹ AMDмІҳлҹј м—¬лҹ¬ мӮ¬мқҙнҒҙм—җ кұёміҗ к°ҷмқҖ лӘ…л №мқ„ мӢӨн–үн•ҳлҠ” кІҪмҡ°лҸ„ мһҲкё° л•Ңл¬ём—җ,
м•„м§Ғ лӘЁлҘёлӢӨ.
м–ҙмЁҢл“ л„“мқҖ SIMD ліҖкІҪмқҖ GPU мҪ”м–ҙмқҳ м»ЁнҠёлЎӨ мҳӨлІ„ н—Өл“ңлҘј мӨ„мқҙкі ,
м „мІҙ м„ұлҠҘ / лӢӨмқҙ нҒ¬кё° / м „л Ҙмқ„ лҶ’мқҙлҠ” нҡЁкіјк°ҖмһҲлӢӨ.
мқҙкІғмқҖ кі мЈјнҢҢлЎң мқён•ң ліөмһЎм„ұ мҰқк°ҖлҘј мғҒмҮ„ н• м§ҖлҸ„ лӘЁлҘёлӢӨ.
мҳҲмғҒліҙлӢӨ нҒ° PowerVR Series6 нҒҙлҹ¬мҠӨн„° кө¬м„ұ
мқҙм „ PowerVR кё°мӮ¬лҘј м“ҙ лӢЁкі„м—җм„ң мқёмҡ© н•ң лё”лЎңк·ё "The rise of GPU compute"лҘј
л°ңкІ¬н•ҳм§Җ м•Ҡм•ҳлӢӨ.
л”°лқјм„ң Rogue м•„нӮӨн…ҚмІҳмқҳ м„ұлҠҘлҸ„ л©ҖнӢ° мҪ”м–ҙ кө¬м„ұмқј к°ҖлҠҘм„ұмқҙ мһҲлӢӨкі мҚјлӢӨ.
н•ҳм§Җл§Ң мқҙкІғмқ„ ліҙл©ҙ лӢЁмқј мҪ”м–ҙ PowerVR G6400 кі„ мөңкі 210GFLOPSлҘј лӘ©н‘ңлЎң м•Ң мҲҳмһҲлӢӨ.
л”°лқјм„ң PowerVR Series6 (Rogue)мқҳ м¶”м • кө¬м„ұлҸ„лҸ„ м •м •н•ҙм•ј н• кІғк°ҷлӢӨ.
Rogue м•„нӮӨн…ҚмІҳлҠ” нҒҙлҹ¬мҠӨн„° кө¬м„ұмқ„ мұ„нғқн•ҳкі мһҲмңјл©°,
м ң 1 м„ёлҢҖлҠ” G6400 кі„к°Җ 4 нҒҙлҹ¬мҠӨн„°,
G6200 кі„к°Җ 2 нҒҙлҹ¬мҠӨн„°лЎң кө¬м„ұлҗңлӢӨ.
нҳ„мһ¬ м•Ңл Ө진 кІғмқҖ нҒҙлҹ¬мҠӨн„°мқҳ м—°мӮ° мң лӢӣ ALU нҢҢмқҙн”„к°Җ 16 к°ң лӢЁмң„лЎңлҗҳм–ҙ мһҲлҠ”м§Җ.
1 нҒҙлҹ¬мҠӨн„° лӢ№ 16 ALU мқё кІҪмҡ°лҠ” G6400 мӢңмҠӨн…ңмқҖ мҙқ 64 ALUлҗҳм–ҙ,
600MHz л•Ңмқҳ м—°мӮ° м„ұлҠҘмқҖ 76.8GFLOPS л°–м—җлҗҳм§Җ м•ҠлҠ”лӢӨ.
к·ёлҹ¬лӮҳ G6400 кі„лҠ” 4 нҒҙлҹ¬мҠӨн„° 210GFLOPSлҘј лӢ¬м„ұн•ҳкё° л•Ңл¬ём—җ,
GPU мҪ”м–ҙмқҳ ALUмқҳ мҲҳлҠ” лҚ” л§Һмқ„ кІғмңјлЎң ліҙмқёлӢӨ.
600MHz лҸҷмһ‘н•ҳл©ҙ кі„мӮ° мғҒмңјлЎңлҠ” 176 ALU мһҲмңјл©ҙ 210GFLOPSм—җ лҸ„лӢ¬н•ҳкІҢлҗңлӢӨ.
4 нҒҙлҹ¬мҠӨн„° кө¬м„ұм—җм„ң 176 ALUмқҳ кІҪмҡ°,
нҒҙлҹ¬мҠӨн„° лӢ№ 44 ALUмҷҖ мҲҳмҠөмқҙ лӮҳмҒң мҲ«мһҗк°Җлҗҳм–ҙ лІ„лҰ°лӢӨ.
н•ңнҺё, ALUк°Җ 16 к°ңм”© 1 к·ёлЈ№м—җ л°”мқёл”©лҗҳм–ҙ мһҲлӢӨкі к°Җм •н•ҳл©ҙ
1 нҒҙлҹ¬мҠӨн„°м—җ 16 ALU нҢҢмқҙн”„к°Җ 3 к°ңм—җм„ң нҒҙлҹ¬мҠӨн„° лӢ№ 48 ALUк°ҖмһҲмқ„кІғ к°ҷмқҖ
кө¬м„ұмқҳ мҲ«мһҗк°ҖлҗңлӢӨ.
4 нҒҙлҹ¬мҠӨн„° кө¬м„ұ G6400лҠ” мҙқ 192 ALUлҗңлӢӨ.
н•ҳм§Җл§Ң 192 к°ңмқҳ ALUлҘј 600MHz мһ‘лҸҷ м„ұлҠҘмқҖ 230GFLOPSлҗҳм–ҙ лІ„лҰ°лӢӨ.
н•ҳм§Җл§Ң, 600MHzлҠ” мөңкі мЈјнҢҢмҲҳм—җм„ң мӢӨм ңлЎң 550MHz м •лҸ„к°Җ нҳ„мӢӨм Ғмқҙлқјкі
Imagination Technologiesмқҙ мЈјмӢңн•ҳкі мһҲлӢӨкі н•ҳл©ҙ,
192 ALU Г— 550MHzм—җм„ң 210GFLOPSлҗңлӢӨ.
Imagination Technologiesмқҳ Web мӮ¬мқҙнҠёмқҳ к·ёлҰјм—җм„ңлҸ„
PowerVR Series6 л¶Җ분мқҖ ~ 600MHzлҗҳм–ҙ, 600MHzлқјкі лӘ…кё°лҗҳм–ҙ мһҲм—ҲлӢӨ.
нҳ„мһ¬ м •нҷ•н•ң мҠӨнҺҷмқҖ лӘЁлҘҙкІ м§Җл§Ң,
м•„л§ҲлҸ„ к°Ғ нҒҙлҹ¬мҠӨн„°м—җ 16 ALUмқҳ к·ёлЈ№мқҙ 3 к°ңм”©лқјлҠ” кө¬м„ұмқҙлӢӨ.
мқҙ 추측мқ„ л°ҳмҳҒн•ң PowerVR Series6 (Rogue) мӢңлҰ¬мҰҲмқҳ м¶”м • кө¬м„ұлҸ„лҠ” м•„лһҳмҷҖ к°ҷмқҙлҗңлӢӨ.
PowerVR Series6 (Rogue)мқҳ м¶”м • лё”лЎқ лӢӨмқҙм–ҙк·ёлһЁ
мҳҲмғҒлҗҳлҠ” GPU нҒҙлҹ¬мҠӨн„°мқҳ кө¬м„ұмқҙ лҚ” нҒ¬лӢӨлҠ” кІғмқҖ
PC мҡ© GPUмҷҖ 비мҠ·н•ң кІғмқ„ мқҳлҜён•ңлӢӨ.
лҳҗн•ң кё°мЎҙмқҳ PowerVR Series5XTмқҳ л©ҖнӢ° мҪ”м–ҙмҷҖ 비көҗн•ҳл©ҙ
м“ёлӘЁм—ҶлҠ” мӨ‘ліө л¶Җ분мқҙ м Ғм–ҙ진лӢӨлҠ” кІғмқ„ ліҙм—¬мӨҖлӢӨ.
нҒҙлҹ¬мҠӨн„°лҘјмқҙ нҒ¬кё°лЎңн•ңлӢӨл©ҙ,
л©ҖнӢ° мҪ”м–ҙлҠ” м•һмңјлЎң мӮ¬мҡ©н•ҳм§Җ м•Ҡкі нҒҙлҹ¬мҠӨн„°лҘј лҠҳлҰ¬лҠ” кІғмңјлЎң
GPUлҘј к°•нҷ”н•ҳлҠ” л°©мӢқмқ„ м·Ён• мҲҳлҸ„мһҲлӢӨ.
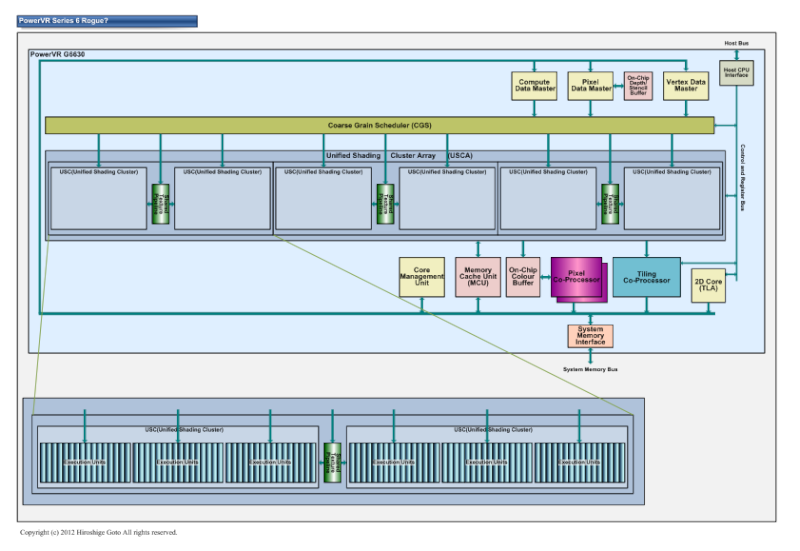
нҒҙлҹ¬мҠӨн„°мқҙмһҗ мөңлҢҖ к·ңлӘЁ н…ҚмҠӨмІҳ мң лӢӣ
PowerVR Series6мқҳ Rogue м•„нӮӨн…ҚмІҳлҠ”
2 нҒҙлҹ¬мҠӨн„° 1 к°ңмқҳ н…ҚмҠӨмІҳ мң лӢӣ кө°мқ„ кіөмң н•ңлӢӨ.
кё°мЎҙмқҳ PowerVR Series5 м•„нӮӨн…ҚмІҳлҠ” н…ҚмҠӨмІҳ мң лӢӣмқҖ мҪ”м–ҙк°„м—җ кіөмң н•ҳлҠ” мһҘм№ҳ мҳҖм§Җл§Ң,
PowerVR Series6м—җм„ңлҠ” нҒҙлҹ¬мҠӨн„°мҷҖ кёҙл°ҖнһҲ нҳ‘л Ҙн•ҳкі мһҲлӢӨ.
л”°лқјм„ң нҒҙлҹ¬мҠӨн„°лҘј лҠҳлҰ¬кі м—°мӮ° м„ұлҠҘмқ„ лҶ’мқҙл©ҙ
лҸҷмӢңм—җ н…ҚмҠӨмІҳ мң лӢӣлҸ„ мҰқк°Җн•ҳкІҢлҗңлӢӨ.
мқҙкІғмқҖ PC мҡ© GPUлҠ” лӢ№м—°н•ҳкі ,
PC мҡ©мңјлЎңлҠ” м—°мӮ°м—җ лҢҖн•ң н…ҚмҠӨмІҳмқҳ 비мңЁмқ„ мқјм •н•ҳкІҢ мң м§Җн•ҳлҠ” кІғмқҙ мӨ‘мҡ” н•ҙм§Җкі мһҲлӢӨ.
PowerVR Series6 н…ҚмҠӨмІҳ мң лӢӣ кө°мқҳ мІҳлҰ¬лҹүмқҖ м•„м§Ғ мҷ„м „нһҲ м•Ңл Өм ё мһҲм§Җ м•ҠлӢӨ.
к·ёлҹ¬лӮҳ ALUмҷҖ н•Ёк»ҳ мҠӨмјҖмқјн•ҳкІҢ лҗң кІғмқҖ мӨ‘мҡ”н•ҳлӢӨ.
лӘЁл°”мқј мһҘм№ҳ мҡ© м• н”ҢлҰ¬мјҖмқҙм…ҳ н”„лЎңм„ём„ңлҠ” мҳӨлһң л©”лӘЁлҰ¬ лҢҖм—ӯнҸӯ лі‘лӘ©мқҙмһҲм—ҲлӢӨ.
н”„лЎңм„ём„ң лӮҙл¶Җмқҳ м„ұлҠҘмқҖ н”„лЎңм„ёмҠӨмқҳ лҜём„ёнҷ”лЎң
нҠёлһңм§ҖмҠӨн„° мҲҳк°Җ лҠҳм–ҙлӮ мҲҳлЎқ мҰқк°Җн•ҳлҠ”лҚ°,
л©”лӘЁлҰ¬ лҢҖм—ӯмқҖ кұ°кё°м—җ м•Ң л§һлҠ” мҶҚлҸ„лЎң мҰқк°Җн–Ҳкё° л•Ңл¬ёмқҙлӢӨ.
л”°лқјм„ң лӘЁл°”мқј GPUлҠ” л©”лӘЁлҰ¬ лҢҖм—ӯнҸӯмқ„ м–өм ң нғҖмқҙ л§Ғ м•„нӮӨн…ҚмІҳк°Җ мқёкё°лҘј лҒҢкі мһҲлӢӨ.
GPU л ҢлҚ”л§Ғ л°©мӢқмқҳ м°Ёмқҙ
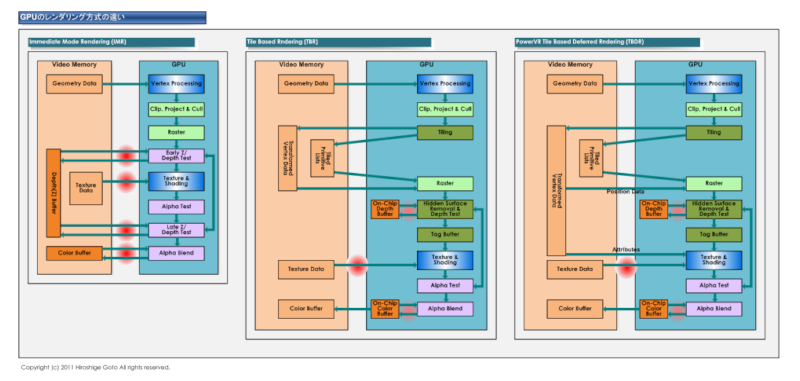
нғҖмқҙ л§Ғ кі„мқҳ м•„нӮӨн…ҚмІҳлҠ”
мҳЁм№© л©”лӘЁлҰ¬лҠ” н”Ҫм…Җ мІҳлҰ¬лЎң
мҷёл¶Җ л©”лӘЁлҰ¬ м•Ўм„ёмҠӨмқҳ н•„мҡ”лҘј м—Ҷм• мӨҖлӢӨ.
н•ҳм§Җл§Ң н…ҚмҠӨмІҳлҘјлЎңл“ңн•ҳлҠ” мҷёл¶Җ л©”лӘЁлҰ¬ м•Ўм„ёмҠӨлҘј м ңкұ° н• мҲҳлҠ” м—ҶлӢӨ.
н…ҚмҠӨмІҳлҠ” мәҗмӢңлҸ„ нҡЁкіј м–ҙл өкё° л•Ңл¬ём—җ
л©”лӘЁлҰ¬ лҢҖм—ӯнҸӯмқҳ м ңм•Ҫмқҙ нҒ¬лӢӨ.
мң„ к·ёлҰјмқҳ мҳӨлҘёмӘҪмқҙ PowerVR м•„нӮӨн…ҚмІҳмқҙм§Җл§Ң,
н…ҚмҠӨмІҳ лҚ°мқҙн„°мқҳ мқҪкё°лЎңл“ң л§Ңмқҙ лӮЁм•„мһҲлҠ” кІғмқ„ м•Ң мҲҳмһҲлӢӨ.
л”°лқјм„ң лӘЁл°”мқј GPUлҠ” м—°мӮ° мң лӢӣмқҳ мҠӨмјҖмқј м—…кіј
н…ҚмҠӨмІҳ мң лӢӣмқҖ 분лҰ¬лҗҳм–ҙмһҲлҠ” кІғмқҙ н•©лҰ¬м Ғмқҙм—ҲлӢӨ.
н”„лЎңм„ёмҠӨмқҳ лҜём„ёнҷ”лЎң м—°мӮ° м„ұлҠҘмқҖ мүҪкІҢ н–ҘмғҒлҗҳлҠ” н•ңнҺё,
л©”лӘЁлҰ¬ лҢҖм—ӯмқҳ м ңм•Ҫмқҙ мһҲкё° л•Ңл¬ём—җ н…ҚмҠӨміҗ мң лӢӣмқҖ лҠҳл ӨлҸ„ мқҳлҜёк°Җ м—Ҷм—Ҳкё° л•Ңл¬ёмқҙлӢӨ.
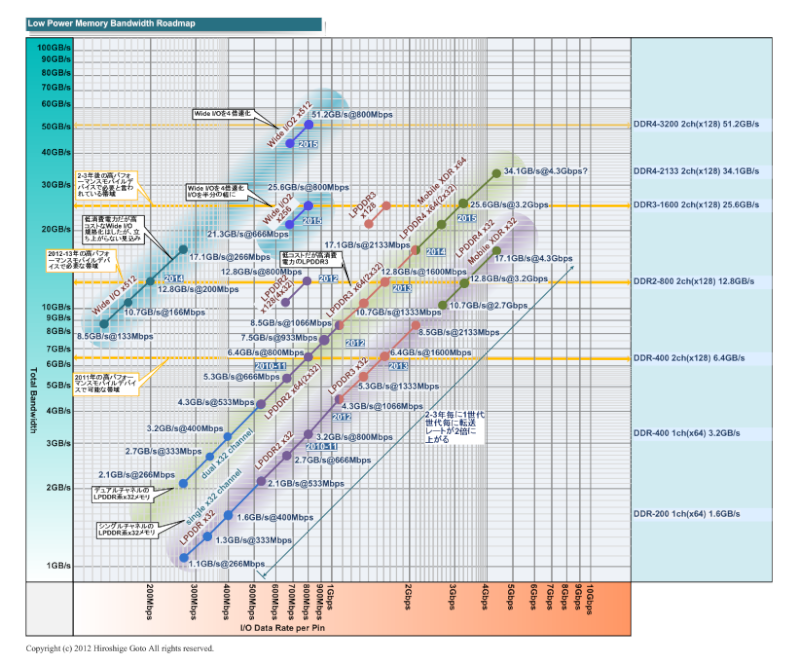
н•ҳм§Җл§Ңмқҙ 2 ~ 3 л…„м—җ лӘЁл°”мқј DRAMмқҳ мғҒнҷ©мқҙ кёүліҖн–ҲлӢӨ.
нҳ„мһ¬лҠ” 2 л…„м—җ 2 л°°мқҳ мҶҚлҸ„лЎң л©”лӘЁлҰ¬ лҢҖм—ӯнҸӯмқҙ нҷ•мһҘлҗҳлҠ” 추세м—җ мһҲмңјл©°,
н”„лЎңм„ёмҠӨ лҜём„ёнҷ”м—җ мқҳн•ң м„ұлҠҘ н–ҘмғҒм—җ л”°лқј мһЎкі мһҲлӢӨ.
м Ғм–ҙлҸ„ 2015 л…„к№Ңм§ҖлҠ” н•ҳмқҙ нҺҳмқҙмҠӨ л©”лӘЁлҰ¬ лҢҖм—ӯнҸӯ н–ҘмғҒмқҙ мқҙм–ҙ진лӢӨ.
лӘЁл°”мқј м Җм „л Ҙ DRAM лЎңл“ңл§ө
PowerVR Series6мқҳ Rogue м•„нӮӨн…ҚмІҳлҠ” мқҙлҹ¬н•ң нҠёл Ңл“ңм—җ лҢҖмқ‘н–ҲлӢӨкі ліј мҲҳлҸ„мһҲлӢӨ.
PowerVR Series6н•ҳм§Җл§Ң м—¬м „нһҲ нғҖмқҙ л§Ғ кі„мқҳ
Tile Based Deferred Rendering (TBDR)"лҘј лҪ‘лҠ” кІғмңјлЎң ліҙмқҙм§Җл§Ң,
н…ҚмҠӨмІҳ мң лӢӣм—җ кҙҖн•ҙм„ңлҠ” мў…лһҳмҷҖ к°ҷмқҙ м—°мӮ° мң лӢӣкіј 분лҰ¬ н• л°©м№Ёмқ„ м·Ён•ҳм§Җ м•ҠлҠ”лӢӨ.
кІ°кіјм ҒмңјлЎң,
PowerVR Series6лҠ” м—°мӮ°кіј лҸҷкё°нҷ” мөңлҢҖ к·ңлӘЁ н…ҚмҠӨмІҳ м„ұлҠҘмқ„ кё°лҢҖн• мҲҳмһҲлӢӨ.
л”°лқјм„ң мӣҗм№ҷм ҒмңјлЎң н…ҚмҠӨмІҳлҘј л§Һмқҙ мӮ¬мҡ©н•ҳлҠ” к·ёлһҳн”Ҫмқ„ мӮ¬мҡ©н•ҳкё° мү¬мӣҢ진лӢӨ.
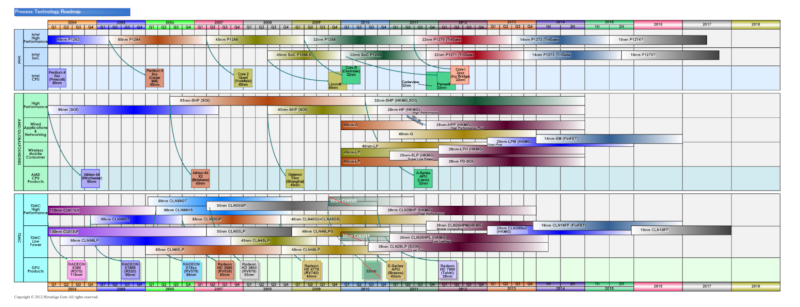
20nm н”„лЎңм„ёмҠӨк°Җ Rogueмқҳ мЈјмҡ” лҢҖмғҒ м—¬л¶Җ
Imagination TechnologiesлҠ”
нҳ„мһ¬ к°ҷмқҖ кі„м—ҙмқҳ GPU м•„нӮӨн…ҚмІҳлҘј
м—¬лҹ¬ н”„лЎңм„ёмҠӨ кё°мҲ мқҳ м„ёлҢҖм—җ кұёміҗ кі„мҶҚн•ҳкі мһҲлӢӨ.
PowerVR Series5 кі„лҠ” 65nm н”„лЎңм„ёмҠӨм—җм„ң 45/40nm,
к·ёлҰ¬кі 32/28nmлЎң мқҙм–ҙм§Җкі мһҲлӢӨ.
PowerVR Series6 (Rogue) мӢңмҠӨн…ңмқҖ 28nm н”„лЎңм„ёмҠӨм—җм„ң мӢңмһ‘н•ҳм§Җл§Ң,
20nmк°Җ л©”мқё нғҖкІҹмңјлЎң,
м•„л§Ҳ 16/14nm н”„лЎңм„ёмҠӨм—җм„ңлҸ„ кі„мҶҚлҗ кІғмңјлЎң 추측лҗңлӢӨ.
PowerVR Series6м—җм„ң TFLOPS нҒҙлһҳмҠӨмқҳ м„ұлҠҘмқ„ лӢ¬м„ұ н• мҲҳ мһҲлӢӨлҠ” Imagination
Technologiesмқҳ л°ңн‘ңлҠ” к·ёлҹ¬н•ң кіјм •мқҳ 진нҷ”лҸ„ м—јл‘җм—җл‘җкі мһҲлҠ” кІғмңјлЎң 추측лҗңлӢӨ.
л§Ңм•Ҫ PowerVR Series6мқҳ 1 нҒҙлҹ¬мҠӨн„°к°Җ 48 ALUлЎң кө¬м„ұлҗҳм–ҙ мһҲлӢӨкі н•ҳл©ҙ,
4 нҒҙлҹ¬мҠӨн„° кө¬м„ұмқҳ PowerVR G6400 кі„м—җм„ңлҠ”
192 ALU кө¬м„ұлҗңлӢӨ.
нҳ„мһ¬ лӘЁл°”мқј SoC мөңлҢҖмқҳ GPUлҘј к°Җ진 Appleмқҳ A6XлҠ” 32nm кіөм •мңјлЎң м ңмЎ°лҗҳм–ҙ
PowerVR SGX554 MP4м—җм„ң 128 ALUлҘј к°–м¶ҳлӢӨ.
28nm кіөм •мңјлЎң м „нҷҳн•ңлӢӨл©ҙ,
мқҙ м •лҸ„мқҳ лӢӨмқҙ нҒ¬кё°м—җм„ң 192 ALUмқҳ GPU мҪ”м–ҙлҘј нғ‘мһ¬ н• мҲҳ мһҲмқ„ кІғмқҙлӢӨ.
мқҙ кІҪмҡ° Appleмқҳ A7X м„ёлҢҖ SoCлҠ” A6Xмқҳ 3 л°°к°ҖлҗҳлҠ”
200GFLOPS нҒҙлһҳмҠӨмқҳ GPU м„ұлҠҘмқ„ лӢ¬м„ұ н• мҲҳмһҲкІҢлҗңлӢӨ.
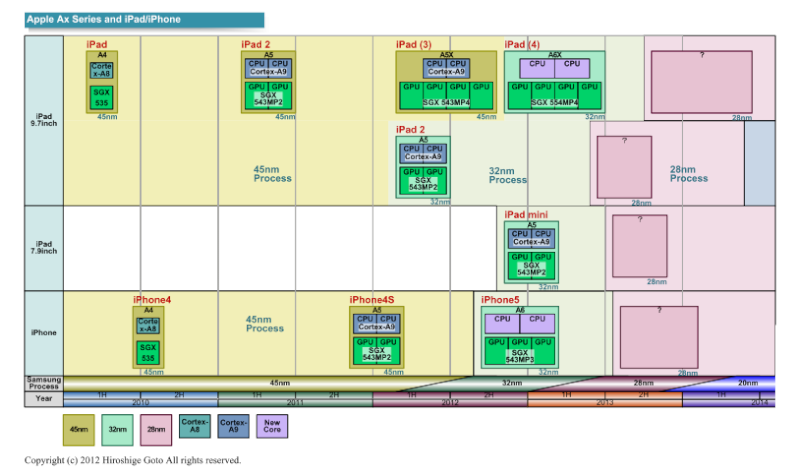
Apple Ax мӢңлҰ¬мҰҲ, iPad / iPhone мӢңлҰ¬мҰҲмқҳ ліҖмІң
лҚ§л¶ҷм—¬м„ң,
Imagination TechnologiesлҠ” PowerVR Series6 (Rogue)мқҳ 2 м„ёлҢҖ мҪ”м–ҙлҘј мқҙлҜё л°ңн‘ңн•ҳкі ,
PowerVR G6630лҠ” 6 нҒҙлҹ¬мҠӨн„° кө¬м„ұлҗңлӢӨ.
к·ёлҹ¬лӮҳ,
28nm н”„лЎңм„ёмҠӨлҠ” 6 нҒҙлҹ¬мҠӨн„°мқҳ G6630мқ„ кІҪм ңм Ғмқё лӢӨмқҙ нҒ¬кё°м—җ л„Јкё° м–ҙл Өмҡё кІғмқҙлӢӨ.
SoC м—…мІҙлҠ” мқҙлҜё 20nm кіөм •мқҳ 칩 м„Өкі„м—җ л“Өм–ҙк°ҖмһҲм–ҙ
6 нҒҙлҹ¬мҠӨн„° PowerVR G6630лҠ” 20nmлҘј лӘ©н‘ңлЎң н•ң кІғмқҙлқјкі 추측лҗңлӢӨ.
мЈјмҡ” нҢҢмҡҙл“ңлҰ¬ н”„лЎңм„ёмҠӨ лЎңл“ңл§ө
 нӣ„лһҳмү¬л§ҲлҰ°
нӣ„лһҳмү¬л§ҲлҰ°








