쌍으로 등장하는 ARM의 CPU 마이크로 아키텍처
ARM은 차세대 64-bit 마이크로 아키텍처 "Cortex-A57 (Atlas)"와
"Cortex-A53 (Apollo)"를 발표했다.
왜, ARM은 2 개의 다른 마이크로 아키텍처의 CPU 코어를 동시에 발표했는지.
그것은 ARM이 다른 특성의 핵심을 결합하여
시스템 전력 소비를 낮추려고하고 있기 때문이다.
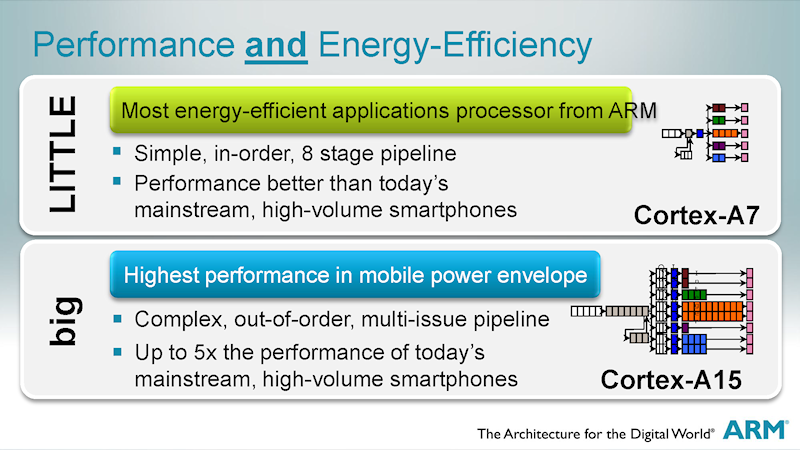
Cortex-A57은 성능에 민감한 대형 코어 Cortex-A53은 저전력의 소형 코어.
ARM은이 두 종류의 CPU 코어를, 부하에 따라 전환하여 전력을 억제하려고하고있다.
ARM은이 아키텍처 "big.LITTLE Processing"라는 이름을 달고있다.
부하가 높은 작업을 수행 할 때 큰 big 코어로 전환 신속하게 처리를 끝낸다.
부하가 낮은 작업이되면 작은 LITTLE 코어에 다시 전력을 억제.
Cortex-A50 시리즈



ARM은 현재 big.LITTLE을 회사의 저전력 기술의 핵심으로 내세우고있다.
따라서 앞으로도 회사의 플래그쉽 CPU 코어는
대형 코어와 소형 코어 쌍으로 등장하게 될 것이다.
사실, Cortex-A57와 Cortex-A53는 big.LITTLE의 2 세대이다.
1 세대에서는 big은 Cortex-A15, LITTLE는 Cortex-A7된다.
big.LITTLE의 1 세대는 이미 모바일 용 SoC (System on a Chip)에
구현 한 제품이 개발되고있어,
소프트웨어 준비가 될 때 2013 년 상반기에서
드디어 big.LITTLE가 현실에 제공 .
big.LITTLE은 시작 직전 단계에 도달 해있다.
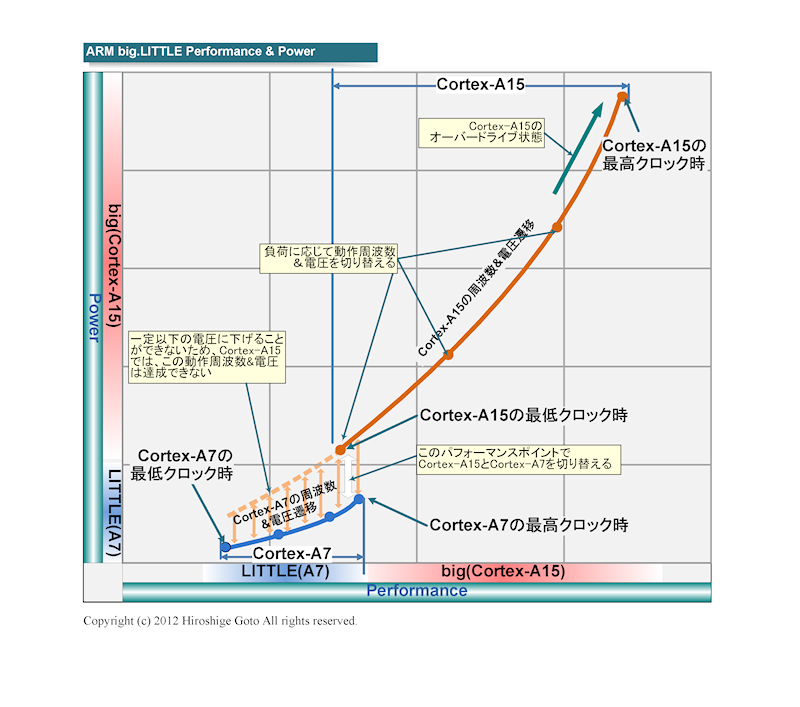
ARM이 big.LITTLE 아키텍처를 도입하는 이유는,
모바일 CPU에 요구되는 성능 범위가 넓은 것에있다.
사용자는보다 쾌적한 응답 및 고급 응용 프로그램을 요구한다.
배터리 구동 시간이 줄어드는 것에 불편하게 느낀다.
따라서 스마트 폰과 태블릿 등의 SoC는
고성능과 초 저전력 모두로 성능 범위를 늘릴 필요성이 있다고 판단.
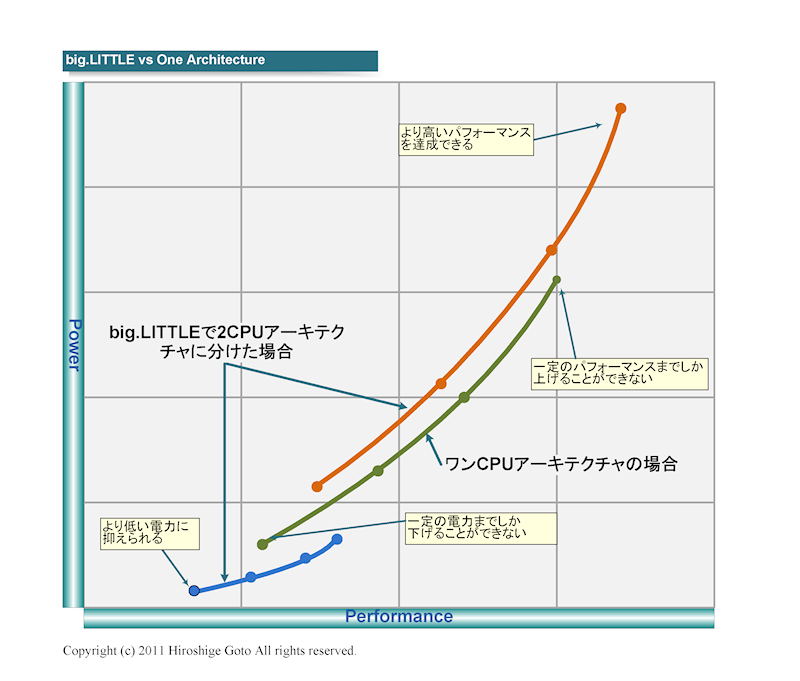
단일 CPU 아키텍처는 고성능과 초 저전력 모두의 요구를 충족하는 것은 어렵다.
하지만 고성능 CPU와 초 저전력 CPU의 2 종류를
작업에서 전환하면 모두의 요구를 충족시킬 수있게된다.
big.LITTLE은 이러한 구상 으로 시작되었다.
big.LITTLE은 Cortex-A15와 Cortex-A7
제 1 세대의 big.LITTLE는 big의 Cortex-A15하면
LITTLE의 Cortex-A7의 2 종류의 CPU 코어를 싣는다.
명령어 세트는 완전 호환 구현된 마이크로 아키텍처는
다른 2 종 코어의 (Heterogeneous : 이종 혼합)이다.
비대칭 멀티 코어 구성이된다.
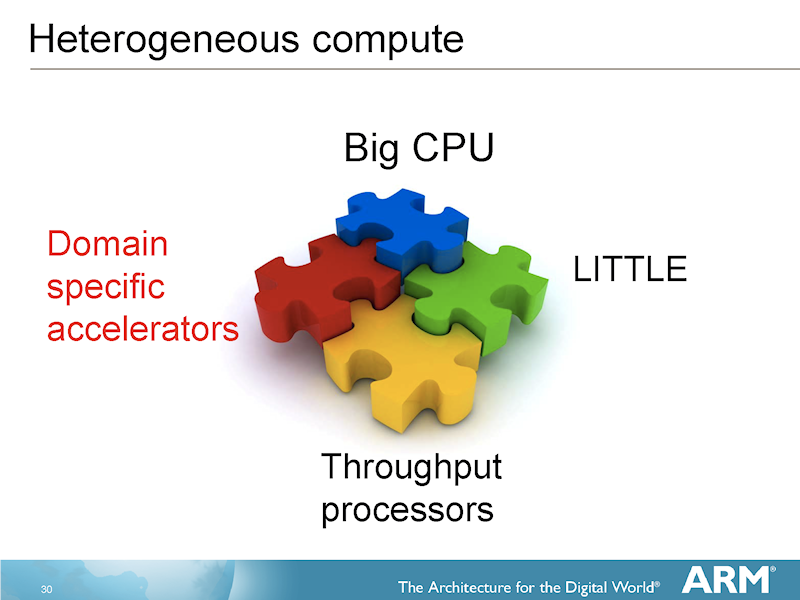
ARM은 이기종 컴퓨팅에 적극적으로 임하고 있지만,
그것은 big와 LITTLE 동 아키텍처 코어 2 종과 GPU 형의 처리량 코어,
그리고 특정 용도 가속기 4 타입의 코어의 조합을 상정하고있다.
그리고 CPU와 GPU의 사이는 LLVM (Low Level Virtual Machine)으로
추상화하는 방법을 잡으려하고있다.
ARM은 big.LITTLE의 이점을 입증하기 위해
내부 테스트 칩을 개발하고 big.LITTLE의 실증 실험을 실시하여왔다.
이는 Cortex-A15이 2 코어,
Cortex-A7가 3 코어 구성에서 성능과 전력의 실증 시험 등을 실시했다.
지난해 단계에서 구상 이었지만 현재는 실증도 끝나고 제품화를 앞두고있다.
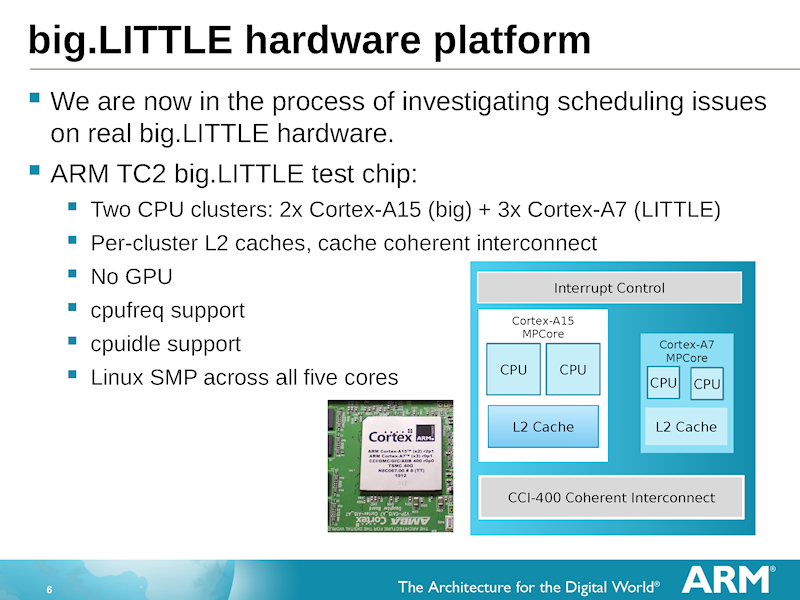
big.LITTLE 하드웨어는 이미 입증이 종료


ARM의 구상은
big.LITTLE에 따라 모바일 컴퓨팅 장치의 SoC는 Cortex-A15/57을 2 ~ 4 코어,
Cortex-A7/53을 2 ~ 4 코어 실은 구성된다.
총 최대 8 코어가 스마트 폰과 태블릿에 타게된다.
실제로, Samsung의 SoC "Exynos"차세대 제품은
4 개의 Cortex-A15와 4 개의 Cortex-A7을 올렸다 옥타 코어 구성이된다.
big.LITTLE의 첫 번째 단계는
기본적으로 big 코어와 LITTLE 코어는 동수 구성이 바람직하다.
동수의 CPU 코어의 사이에서만 빠르고 간단한 작업을 전환 할 수 없기 때문이다.
또한 하드웨어 적으로는 인터럽트 컨트롤러를 공유하여
인터럽트를 전환 할 필요가있다.
또한 big와 LITTLE 모두 CPU 클러스터간에 일관된 버스로 연결하는 것으로,
CPU 코어 아키텍처 르 스테이트를 캐시를 통해 전달할 수 있도록한다.
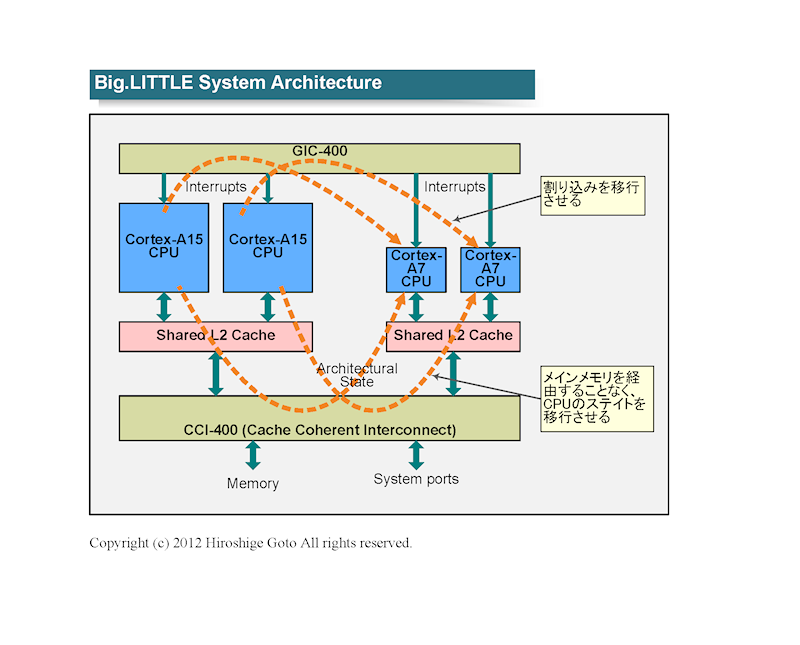
big.LITTLE 시스템 아키텍처
big.LITTLE의 개념
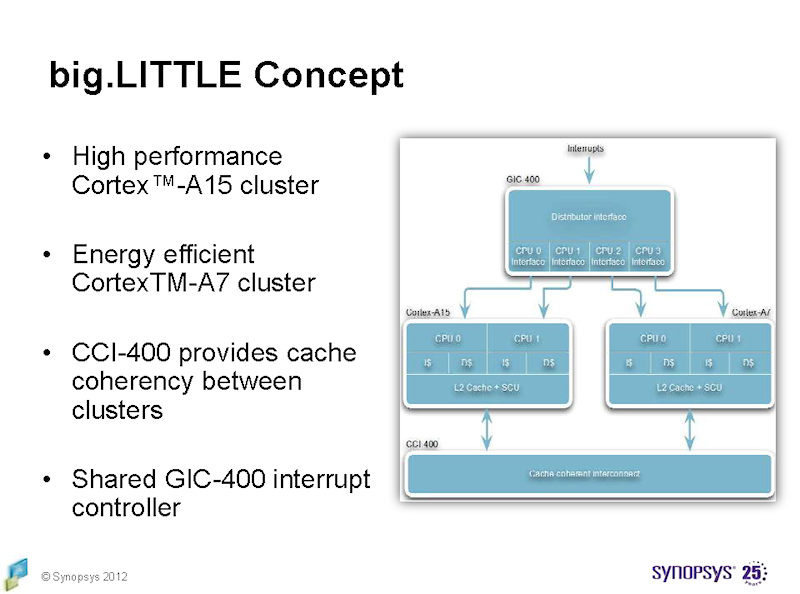
후자의 방법을 위해,
CPU 코어 간의 작업 전환시에 스테이트를 외부 메모리에 기록 할 필요가 없다.
따라서 스위칭 시간이 최소화된다.
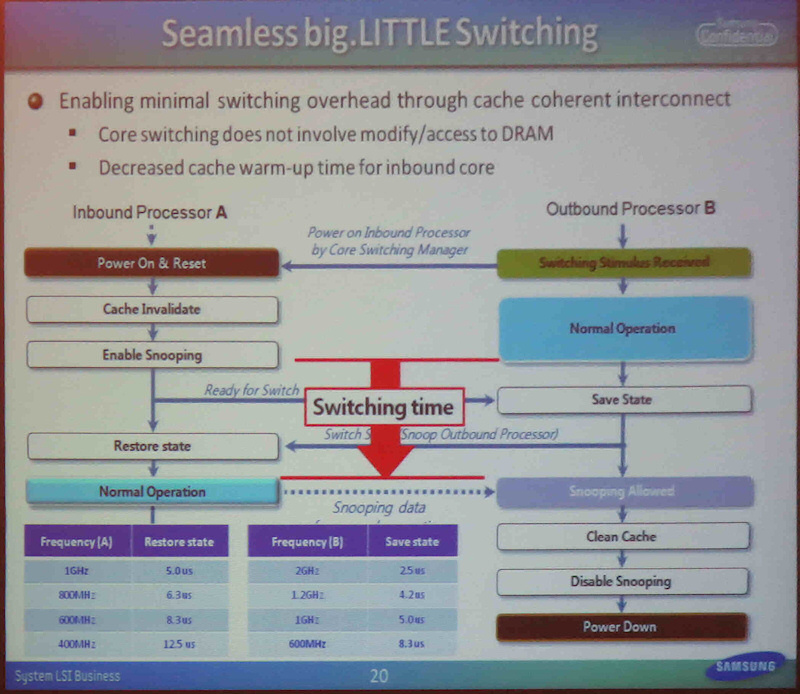
실제로는 CPU 코어를 시작하는 데 시간이 걸리지 만,
그동안은 현재 작업을 실행하는 코어를 달리게함으로써 은폐한다.
CPU 코어 간의 작업 스위치에 의해 처리가 멈추는 블랙 아웃 기간은 해제
CPU 코어 아키텍처 .
/르 스테이트/를 캐시에 사용한 CPU 코어에 복원 할 때까지의 시간이다.
스테이트의 저장 시간은 CPU 코어의 주파수에 따라 다르지만
600MHz로 전환한다면 8.3us.
스테이트의 복원은 동일한 주파수라면이 시간.
전환 주파수를 낮게하면할수록 보존과 복원에 걸리는 시간은 길어진다.
ARM의 설명에 따르면, 최소는 블랙 아웃은 20us 정도까지 억제된다고한다.
big.LITTLE 구현 : 내부 연결 IP
원활한 big.LITTLE 스위칭
big.LITTLE 구현 : GIC

big.LITTLE 작업 전환
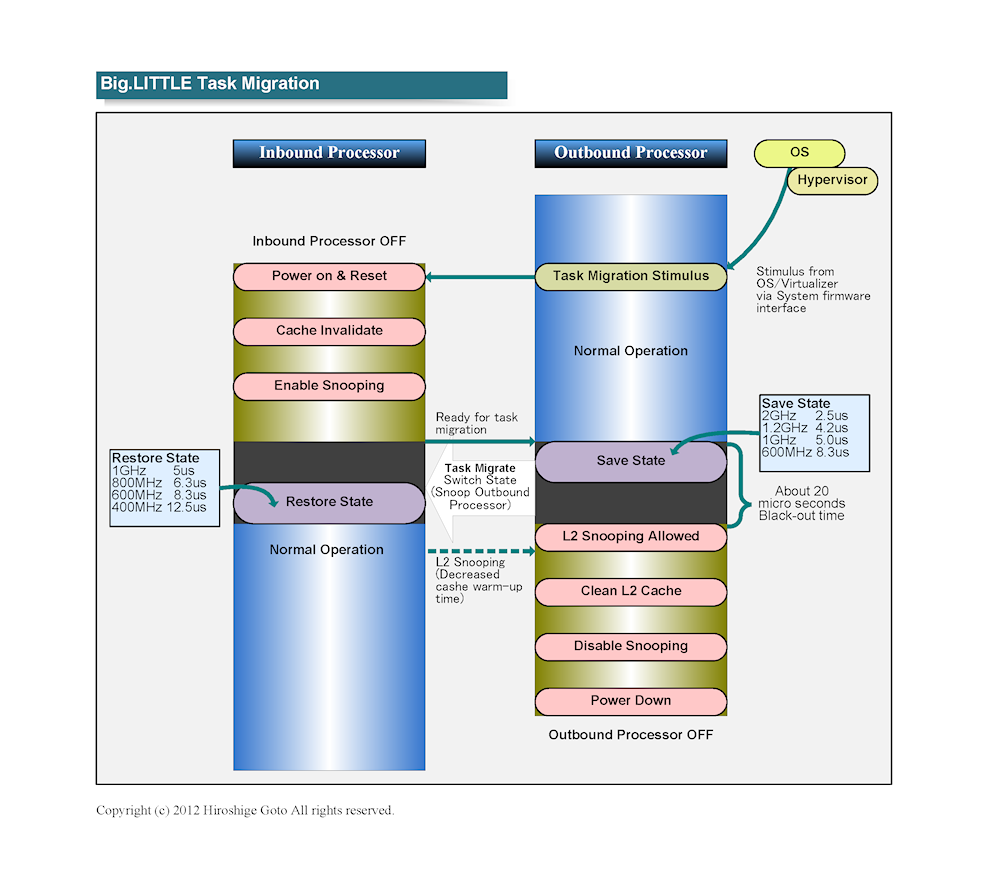
ARM의 big.LITTLE 구성에서는 L2까지 캐시는 클러스터에 포함되어 있으며,
big과 LITTLE간에 공유되지 않는다.
이것은 LITTLE 코어의 캐시를 작고 저전력에 할 수 있도록했기 때문이다.
따라서 작업을 전환 한 경우에는 캐시의 플래시와 워밍업 지연도 발생한다.
그래서 big.LITTLE는 그 시간을 은폐하는 구조도 통합했다.
해제 한 CPU 코어의 캐시를 플러시하고
DRAM에 다시 켜진 CPU 코어가 스눕 할수 있도록한다.
이러한 노력으로 작업 전환 시간을 단축하고있다.
클러스터 기반에서 CPU 코어 기반으로 발전
작년 가을에 big.LITTLE을 ARM이 발표 한 때 big와 LITTLE 스위치는
클러스터 단위로 밖에 할 수 없었다.
예를 들어, 4CPU 코어 Cortex-A15 클러스터와
4CPU 코어 Cortex-A7 클러스터에서 스위치한다.
클러스터 마이그레이션 모델은 부하가 높은 작업에 끌려
모든 코어가 고성능 코어에 바뀌어 버리기 때문에 효율이 나빴다.
그래서 이번에는 CPU 코어 단위로 전환하는 CPU 마이그레이션 모델이 마련됐다.
사실,이 CPU 마이그레이션 모델 big.LITTLE을 초래하는.
초기 개념의 클러스터 마이그레이션 모델은
2011 년에 프로토 타입 소프트웨어가 제공되었지만,
현재는 정식 모델로는 제공되지 않는다.
CPU 마이그레이션 모델은
big 클러스터의 CPU 코어는 LITTLE 클러스터의 CPU 코어와 1 대 1로 쌍으로 스위치한다.
따라서 부하가 높은 작업을 수행하는 경우
필요한 수의 CPU 코어 만 big 코어 스위치하고
코어 LITTLE 코어 그대로 작동시킬 수있다.
보다 효율적이고 전력을 효과적으로 억제 할 수있다.
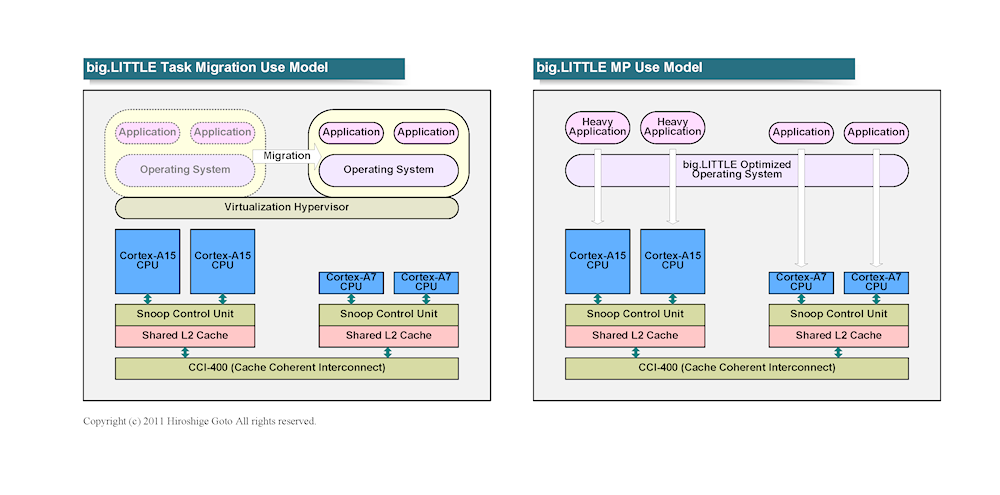
big.LITTLE 이용 모델


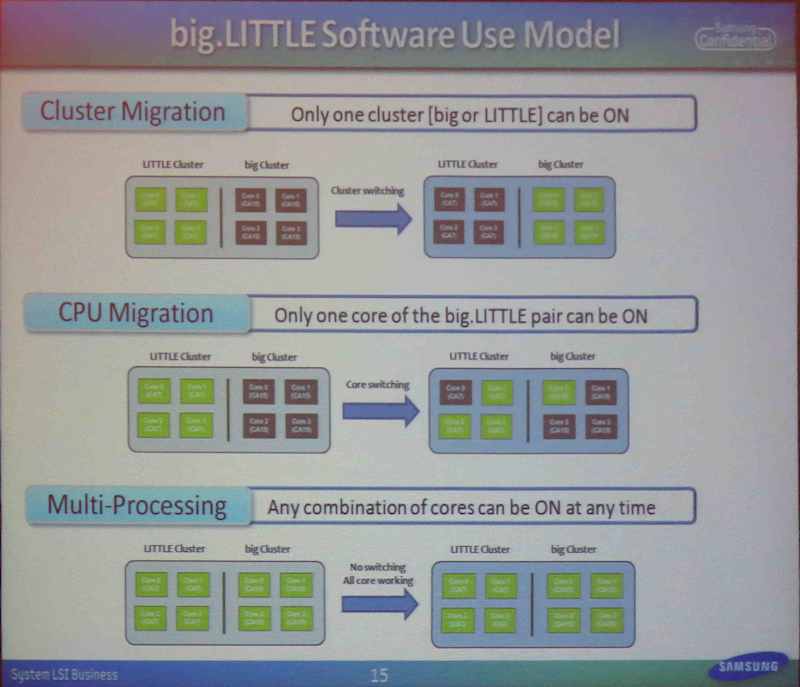
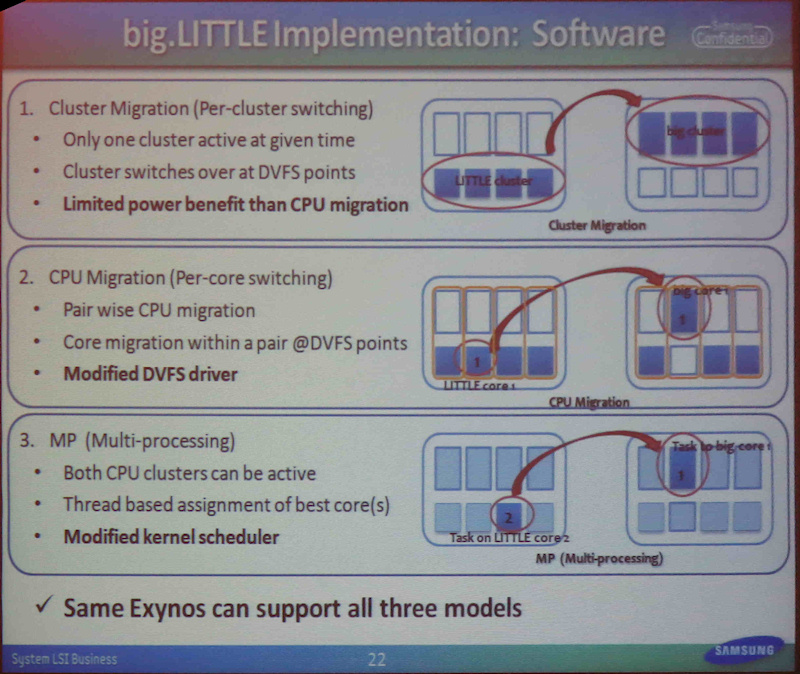
클러스터 마이그레이션도
CPU 마이그레이션도 모두 소프트웨어 측의 변경이 작아도된다.
응용 프로그램과 시스템 아키텍처는 변경이 전혀 필요 없다.
작업 마이그레이션 트리거는 가상화를 사용할 경우
Hypervisor가 발행, OS 측에서 추상화된다.
작업이 전환되는 점 자체는
CPU의 전압과 동작 주파수를 전환 "DVFS (Dynamic Voltage and Frequency Scaling)"의
단계에 통합된다.
big 코어가 일정한 주파수까지 떨어지면
LITTLE 코어로 전환 트리거가 발행된다.
LITTLE에서 big의 경우는 반대로 특정 주파수에 오르면 바뀐다
OS에 이미 DVFS 방식을 사용하기 때문에 구현이 용이하다.
또한 ARM은 완전히 이기종 동작하는 멀티 프로세싱 모델
"big.LITTLE MP"도 제공한다.
이 경우, OS가 작업을 예약하고 비용이 많이 드는 작업을
big 코어에 부하가 적은 작업을 LITTLE 코어에 할당해야합니다.
이쪽도 하드웨어 측면의 변화는없이 소프트웨어 측만의 대응이지만,
OS의 지원이 필요하기 때문에 시간이 걸린다. 현재 개발중인 표명되어있다.
big.LITTLE 소프트웨어 아키텍처
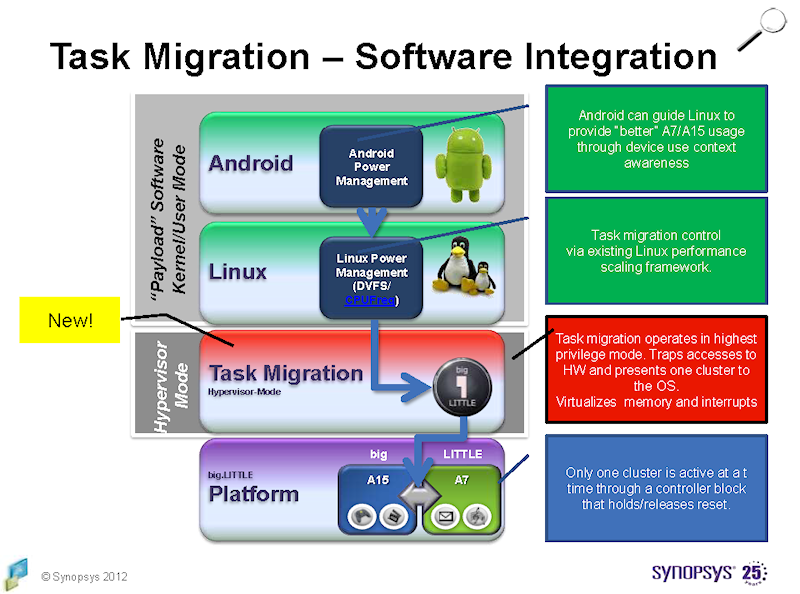



big.LITTLE에 솔깃한 Samsung
10 월에 미국에서 개최 된 ARM 기술 컨퍼런스 "ARM Techcon 2012"은
Samsung이 big.LITTLE 대한 자세한 세션을 진행했다.
Samsung에 따르면,
이미 Cortex-A15 기반 Exynos에 Cortex-A7을 통합
big.LITTLE의 검증을 행하고 있다고한다.
실제 칩 기반이기 때문에,
Samsung의 발표는 구체적이다.
Samsung의 검증 시스템은
big의 Cortex-A15는 800MHz에서 1.7GHz로 동작,
LITTLE의 Cortex-A7은 200MHz에서 1GHz로 동작.
전압은 0.9에서 1.2V로 전환한다.
Cortex-A15에서 Cortex-A7로 전환하는 아래의 임계 값은
Cortex-A15에서 800MHz로 설정했다고한다.
반대로 Cortex-A7에서 Cortex-A15에 임계 값은 Cortex-A7에서 1GHz이다.

Exynos의 검증 결과
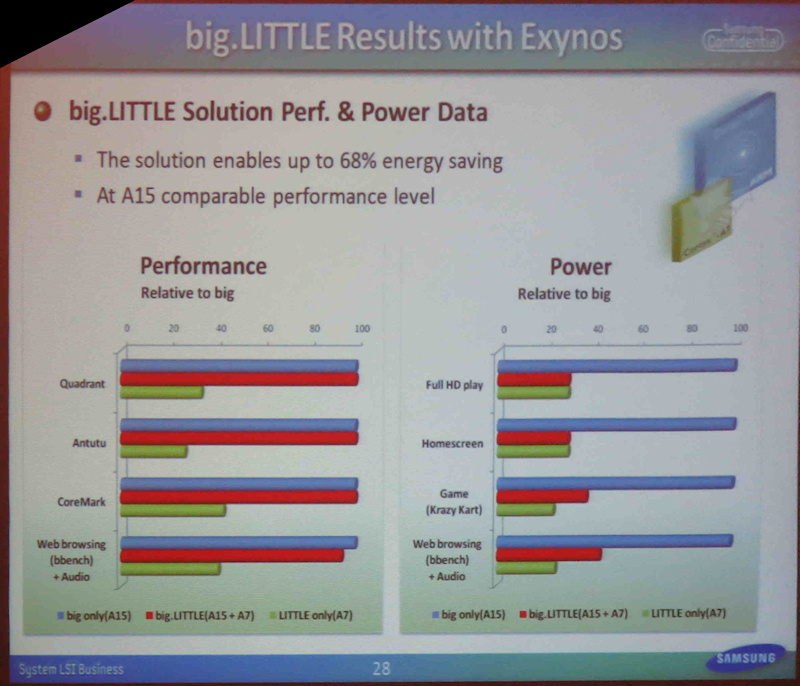
이 시스템의 검증 결과,
성능은 Cortex-A15 만의 시스템과 거의 동등 전력
반대로 최대 68 % 줄일 수 있었다고한다.
전력 절감 효과가 극적인 것은
실제로는 작업의 대부분이
LITTLE 코어에서 처리 할 수있는 정도의 부하 것으로 차지하고 있기 때문이다.
아래의 차트는 Cortex-A9의 부하를 나타낸 것이지만,
big 코어가 필요한 붉은 부분은 극히 제한되어 있는지 알 수있다.
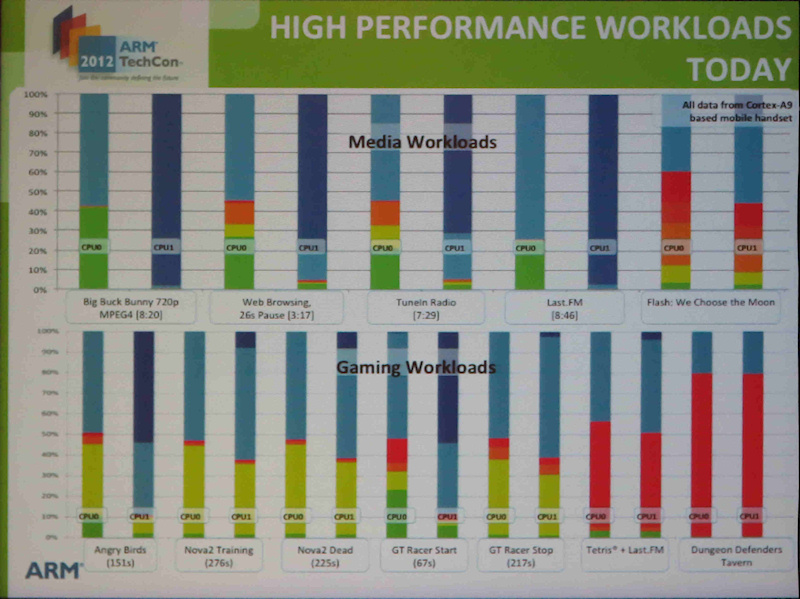
big.LITTLE 아키텍처가 발표 된 2011 년 가을 단계에서는
과연 라이센스의 SoC 업체들이 오는지 여부 미지수였다.
ARM은 "OEM의 반응은 좋다"고 설명했지만,
실제 제품 계획은 입증되지 않았다.
그러나 현재는 Samsung이 적극적으로 대응하고,
전망이 좋다.
x86에서 big.LITTLE을 목표로 한 Montalvo
이대로 ARM의 의도대로 진행된다면,
ARM 기반의 모바일 기기에서 big.LITTLE에서
크고 작은 코어를 갖추는 것이 당연하게 되어 갈 가능성이있다.
ARM은 Cortex-A7/53의 핵심은 매우 작기 때문에 구현이 진행될 것으로보고있다.
big.LITTLE은 ARM 만의 특권인가.
이 방법은 PC의 세계에 가져올 수없는 것일까.
물론 PC도있다.
원래, big.LITTLE과 비슷한 아이디어는 이전부터 여러 번 등장했다.
그리고 x86 호환 CPU의 세계에서도,
big.LITTLE적인 아이디어를 실현하려는 움직임이 있었다.
가장 두드러진 예는 실리콘 밸리의 CPU 벤처 Montalvo Systems이었다.
Montalvo 원래 NexGen의 Vinod Dham 씨와 원래 Transmeta CEO의 Matt Perry 씨,
Microprocessor Report의 애널리스트들 등 다채로운 멤버가 모인 기업이었다.
이 회사는 x86 호환 대형 CPU 코어와 소형 CPU 코어를 결합한
비대칭 멀티 코어 CPU를 개발하려고했다.
부하가 높은 어플리케이션은 대형 코어에서
부하가 낮은 응용 프로그램은 소형 코어에서 실행하는 구조 다.
Montalvo의 오리지날 플랜의 자세한 것은 모르지만,
기본 아이디어는 big.LITTLE과 비슷하게 보인다.
당시 Montalvo의 관계자는 2009 년경에는
제품의 설명을 미디어에 행할 것이라고 말하고 있었다.
그러나 Montalvo는 Sun Microsystems에 인수되면서
Sun 자체도 Oracle에 인수되어 그 말썽에서 Montalvo의 x86도 사라져 버렸다.
덧붙여서, Montalvo의 개발 팀은 산산조각했지만,
일부는 NVIDIA에 갔다고 전해진다.
ARM이 big.LITTLE을 발표하기 전에
NVIDIA가 Tegra 3에서 Cortex-A9의 성능 최적화 쿼드 코어와
전력 최적화 단일 코어 스위치 아키텍처를 도입하고있다.
Montalvo은 사라졌지 만,
회사의 시도는 x86에서도 같은 아이디어가 가능하다는 것을 보여주고있다.
그리고, Intel도AMD도
고성능의 x86 CPU 코어와 저전력 x86 CPU 코어의 2 종류가있다.
Intel라면 22nm 세대의 "Haswell (하스웰)"와
22nm의 Atom 코어 "Silvermont (실버 몬트)"의 조합 수있을 것 같다.
AMD라면, 28nm에서 Bulldozer 계의 "Steamroller (스팀 롤러)"와
Bobcat 계의 "Jaguar (재규어) '에서 비슷한 접근 할 수있을 것 같다.
또한 Intel은 실수 없게 연구도하고있다.
예를 들어, 컴퓨터 아키텍처 학회
"International Symposium on Computer Architecture (ISCA '12)"에서 "Scheduling Heterogeneous Multi-Cores through Performance Impact Estimation (PIE)"라는
제목의 공동 연구 논문에서 big.LITTLE 형 CPU 구성 의 성능 예측 연구를 수행하고있다.
Intel은 이전부터 HPC (High Performance Computing)
분야에서 같은 명령 세트 아키텍처의
big와 LITTLE 조합의 연구를 실시하고 있으며,
이 접근법의 가능성에 대해서도 주목하고있다.
 후래쉬마린
후래쉬마린















